机器学习理论 (1)
包括绪论, 评估标准和线性回归的内容
第一章绪论
1. 基本术语
- 样本 : 单个数据 , 用向量表示
- 样本空间 : 向量空间
- 数据集 : 好多好多数据
- 模型 : 有输入输出的模块
- 标记: 单条数据的标记
区分分类问题, 连续值, 概率 - 泛化: 对未知事物的判断准确性
- 分布: 样本空间的概率分布
2. 假设空间
- 假设空间:
用数学表达式或者神经网络模型, 来假设解决问题的方法, 比如说对于线性模型, 可以假设
其中 w 和 b 是固定的
- 版本空间
量化真相的模型和参数. 一定存在, 但是我们的假设不一定能到达
3. 归纳偏好
可以有多个模型来预测同一个问题, 比如说一元线性模型和多项式模型可以对同一个问题进行建模
奥卡姆剃刀原则:
若有多个假设与观察一致,则选最简单的那
第二章 模型评估
1. 经验误差和过拟合
- 错误率 :
其中m为样本个数,a为分类错误样本个数。 - 精度 = 1 - 错误率。
- 误差:学习器的实际预测输出与样本的真实输出之间的差异。
- 经验误差:学习器在训练集上的误差,又称为”训练误差”。
- 泛化误差:学习器在新样本上的误差。
- 过拟合是由于模型的学习能力相对于数据来说过于强大
- 欠拟合是因为模型的学习能力相对于数据来说过于低下
2. 评估方法
留出法 :
把数据集切分成为训练集和验证集, 用来 做验证
(K折)交叉验证法:
把数据集切分为多个子集, 一个做测试集, 剩下的用于训练, 训练并行进行
最后的结果取多次训练的平均
自助法(Bootstrap):
假设原始数据集有 N 个样本:
生成自助样本:
- 从原始数据集中有放回地随机抽取 N 个样本,组成一个训练集(bootstrap sample)。
- 由于是有放回抽样,部分样本会被重复选中,部分样本不会被选中。
确定测试集(OOB 样本):
- 没有被选中的样本构成“袋外样本”(Out-of-Bag, OOB),用于测试模型。
训练与评估:
- 在自助样本上训练模型。
- 用 OOB 样本计算模型的性能(如准确率、F1、MSE 等)。
重复多次(如 B = 100 或 1000 次):
- 每次生成不同的自助样本和对应的 OOB 测试集。
- 得到 B 个性能评估值。
- 数学原理简析
- 每次抽样,某个样本未被抽中的概率是:
所以,平均约有 36.8% 的样本会成为 OOB 样本,可用于测试 —— 这与“留一法交叉验证”的测试比例类似。
3. 性能度量
本节性能度量指标较多,但是一般常用的只有错误率、精度、查准率、查全率、F1、ROC和AUC。
这七个指标构成了分类模型评估的“核心工具箱”。没有最好的指标,只有最适合当前任务的指标。理解它们的含义、计算方式和适用场景,是构建可靠机器学习系统的关键一步!
🎯 3. 1基础概念:混淆矩阵(Confusion Matrix)
在讲解这些指标前,必须先理解混淆矩阵 —— 所有指标的“母体”。
假设是一个二分类问题(正类=1,负类=0),模型预测结果可以分为四种:
| 预测为正例 (1) | 预测为负例 (0) | |
|---|---|---|
| 真实为正例 (1) | TP(真正例) | FN(假负例) |
| 真实为负例 (0) | FP(假正例) | TN(真负例) |
📌 说明:
- TP (True Positive):真实是正例,预测也为正例 → 正确抓到了
- FN (False Negative):真实是正例,预测为负例 → 漏掉了(“没抓到坏人”)
- FP (False Positive):真实是负例,预测为正例 → 误报了(“冤枉好人”)
- TN (True Negative):真实是负例,预测也为负例 → 正确排除了
✅ 3. 2 常用性能度量指标详解
1️⃣ 错误率(Error Rate)
定义:预测错误的样本占总样本的比例。
🔹 举例:100个样本,错了10个 → 错误率 = 10%
🔹 特点:
- 最直观,但在类别不平衡时容易误导。
- 例如:99个负例,1个正例,模型全预测负例 → 错误率只有1%,但正例完全没识别出来!
2️⃣ 精度 / 准确率(Accuracy)
定义:预测正确的样本占总样本的比例。
🔹 和错误率是“互补关系”。
🔹 适用场景:
- 类别分布均衡时效果好。
- 类别极度不平衡时(如欺诈检测、罕见病诊断),精度会虚高,不可靠!
3️⃣ 查准率(Precision,精确率)
定义:预测为正例的样本中,有多少是真正的正例?
🔹 关注点:“我抓到的‘坏人’里,有多少是真的坏人?”
🔹 高查准率 = 少误报(FP少)
🔹 适用场景:
- 希望尽量减少“误伤”(如垃圾邮件识别、司法判决)
- 宁可漏掉一些,也不要冤枉好人!
4️⃣ 查全率(Recall,召回率,灵敏度 Sensitivity)
定义:所有真实正例中,有多少被模型找出来了?
🔹 关注点:“所有真正的‘坏人’,我抓到了多少?”
🔹 高查全率 = 少漏报(FN少)
🔹 适用场景:
- 希望尽量“宁可错杀,不可放过”(如癌症筛查、安全监控)
- 宁愿误报,也要把真正的正例都找出来!
📌 查全率 = 真正例率(TPR)= Sensitivity
5️⃣ F1 分数(F1-Score)
定义:查准率和查全率的调和平均数,用于综合评估两者。
🔹 为什么用调和平均?
- 比算术平均更“严格”:如果其中一个很低,F1 会很低。
- 适用于查准率和查全率需要平衡的场景。
🔹 Fβ 分数(扩展):
- 如果更重视查全率:用 F2(β=2)
- 如果更重视查准率:用 F0.5(β=0.5)
6️⃣ ROC 曲线(Receiver Operating Characteristic Curve)
定义:以“假正例率(FPR)”为横轴,“真正例率(TPR = Recall)”为纵轴,绘制的曲线。
FPR(假正例率) =
→ 负样本中被误判为正的比例
TPR(真正例率) =
= Recall
🔹 ROC 曲线怎么画?
- 改变分类阈值(比如从0.1到0.9),每个阈值得到一个(FPR, TPR)点,连成曲线。
🔹 理想情况:
- 曲线越靠近左上角越好 → TPR高,FPR低
- 对角线(随机猜测)是基准线
7️⃣ AUC(Area Under ROC Curve)
定义:ROC 曲线下的面积,用于量化模型整体排序能力。
- AUC ∈ [0.5, 1.0]
- 0.5:随机猜测
- 1.0:完美分类器
🔹 AUC 的直观理解:
“随机选一个正样本和一个负样本,模型给正样本打分高于负样本的概率”
🔹 优点:
- 不依赖分类阈值
- 对类别不平衡不敏感
- 适合评估排序能力(如推荐系统、信用评分)
📊 3. 3 如何选择指标?—— 场景导向!
| 场景 | 推荐指标 | 原因说明 |
|---|---|---|
| 类别均衡,简单分类 | Accuracy | 直观,计算简单 |
| 垃圾邮件识别 | Precision | 少误判正常邮件(避免打扰用户) |
| 癌症筛查、故障检测 | Recall | 少漏诊(宁可误诊,不可漏诊) |
| 综合评估模型 | F1 | 平衡 Precision 和 Recall |
| 比较多个模型排序能力 | AUC | 与阈值无关,适合模型横向比较 |
| 需要可视化模型性能变化 | ROC 曲线 | 看不同阈值下的权衡 |
| 极度不平衡数据 | Precision, Recall, F1, AUC | Accuracy 会失效 |
🧠 3.4 一句话总结每个指标
- 错误率 → “我错了多少?”
- 精度(Accuracy) → “我答对了多少?”
- 查准率(Precision) → “我说是的,有多少是真的?”
- 查全率(Recall) → “真的,我找到了多少?”
- F1 → “Precision 和 Recall 的综合打分”
- ROC → “不同阈值下,模型抓正例 vs 误判负例 的表现曲线”
- AUC → “ROC 曲线下面积,越大越好,衡量模型排序能力”
📌 3. 5 小贴士 & 常见误区
⚠️ 误区1:Accuracy 高 = 模型好?
→ 不一定!在不平衡数据中 Accuracy 会欺骗你!
⚠️ 误区2:只看 Precision 或只看 Recall?
→ 要根据业务目标权衡!医疗看 Recall,广告看 Precision。
⚠️ 误区3:AUC 高 = 模型一定实用?
→ AUC 衡量的是“排序能力”,不是“分类效果”。如果阈值选得不好,实际 Precision 可能很低!
✅ 建议:
- 画出混淆矩阵,看具体 TP/FN/FP/TN
- 同时报告 Precision、Recall、F1
- 用 ROC-AUC 做模型比较
- 根据业务目标调整阈值(比如用 Precision-Recall Curve 找最佳点)
✅ 3.6 附:多分类怎么办?
上述指标主要针对二分类,但在多分类中也可用:
- 宏平均(Macro-average):每个类别单独计算指标,再取平均(平等对待每个类)
- 微平均(Micro-average):汇总所有类别的 TP/FP/FN/TN,再计算(大类主导)
- 加权平均(Weighted):按类别样本数加权平均
例如:
from sklearn.metrics import classification_report
print(classification_report(y_true, y_pred))输出包含每个类的 Precision、Recall、F1,以及宏/微平均值。
4 . 比较检验
取得的性能度量是随机变量, 应该有置信区间(这部分完全是理论研究, 可以跳过)
5. 偏差与方差
估计出来的真实值
为了评估和真实结果之间的度量, 我们一般用偏差和方差来进行度量
第三章 线性模型
1. 基本形式
这个是数学可以表达的, 因为是线性的, 然后我们一般最小化误差, 来求我们的参数w 和 b
因为是数学可以解释的,所以一般可以用极大似然估计 或者最小二乘法来估计我们的 w 和 b
但其实后面的所有解法都是梯度下降. 这里不做公式推导了, 没啥用很鸡肋
- 比如说最小化均方误差
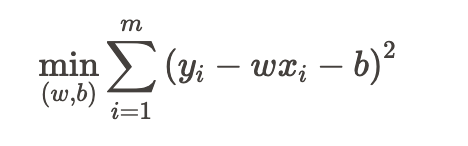
- 向量表示为:
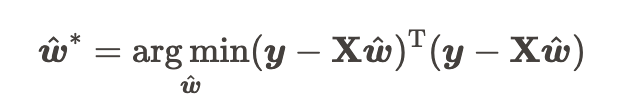
📘 2. 对数几率回归(Logistic Regression)
⚠️ 注意:虽然叫“回归”,但它是分类算法!
✅ 1. 基本思想
线性回归输出的是连续值,不适合分类。对数几率回归通过对线性回归结果进行“非线性映射”,将其压缩到 [0,1] 区间,表示“属于正类的概率”。
✅ 2. 核心公式
(1)线性部分:
(2)Sigmoid 函数(对数几率函数):
- 输出 ∈ (0,1),可解释为“样本属于正类的概率”
(3)决策规则:
- 若
→ 预测为正类(1) - 否则 → 预测为负类(0)
✅ 3. 为什么叫“对数几率”?
“几率(odds)” =
,表示“正例概率 vs 负例概率”
对数几率:
→ 所以叫“对数几率回归”:用线性模型拟合对数几率
✅ 4. 损失函数:交叉熵损失(极大似然推导)
对于二分类:
其中
→ 用梯度下降优化
✅ 5. 优点
- 输出具有概率意义
- 可解释性强(系数 w 反映特征重要性)
- 计算高效,适合大规模数据
- 常作为 baseline 模型
3. 线性判别分析(LDA, Linear Discriminant Analysis)
🧠 LDA 是一种有监督的降维 + 分类方法,与 PCA(无监督)不同。
✅ 1. 基本思想
LDA 希望找到一个投影方向,使得:
- 同类样本投影后尽可能近(类内方差小)
- 不同类样本投影后尽可能远(类间方差大)
→ 最大化“类间散度 / 类内散度”
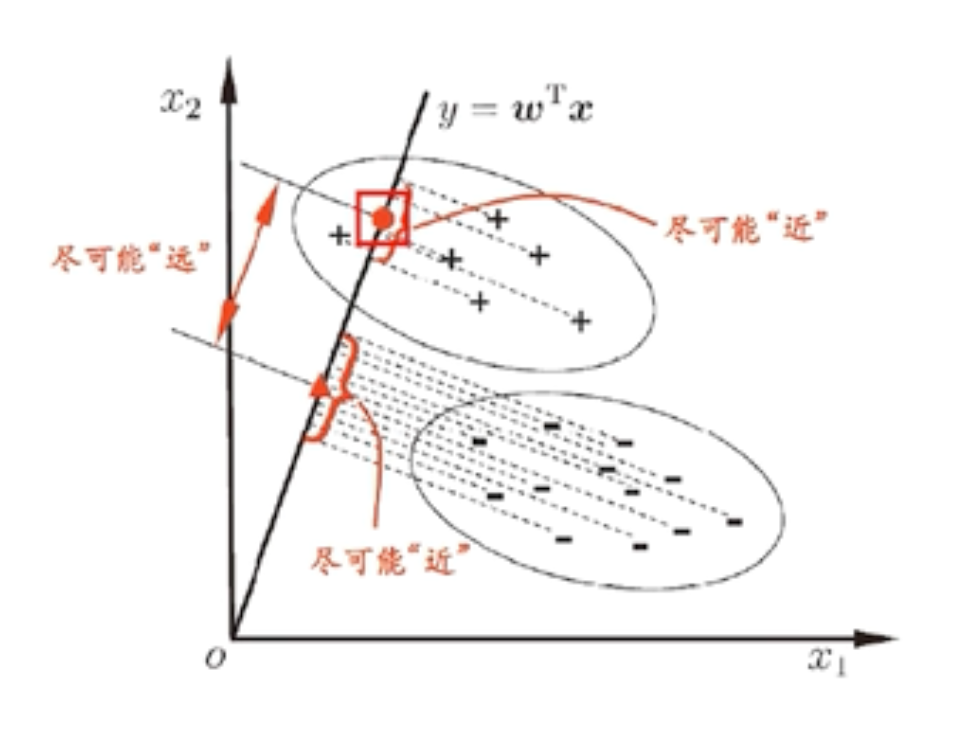
✅ 2. 核心公式(二分类)
定义:
:负类、正类均值向量 :负类、正类协方差矩阵 - 若假设两类协方差相等(
),则投影方向为:
→ 投影后用阈值分类(如中点)
✅ 3. 与逻辑回归的区别
| 特性 | 逻辑回归 | LDA |
|---|---|---|
| 假设 | 无分布假设 | 假设各类服从高斯分布,且协方差相等 |
| 输出 | 概率 | 判别边界 |
| 小样本表现 | 容易过拟合 | 在小样本且满足假设时表现更好 |
| 多分类 | 需扩展(如 One-vs-Rest) | 原生支持 |
| 降维能力 | 无 | 有(可降至 C-1 维,C=类别数) |
📌 LDA 更适合:数据近似高斯分布 + 类别协方差相似 + 小样本
4. 多分类学习(Multiclass Learning)
二分类算法(如逻辑回归、SVM)如何扩展到多分类?
✅ 1. 三种主流策略
(1)One-vs-Rest(OvR,一对多)
- 对每个类别,训练一个“该类 vs 其他所有类”的二分类器
- 共训练 K 个分类器(K=类别数)
- 预测时,选择概率最大/得分最高的类
✅ 优点:简单,几乎所有二分类器都支持
❌ 缺点:类别不平衡(“其他类”样本远多于“该类”)
(2)One-vs-One(OvO,一对一)
- 对每两个类别训练一个二分类器
共训练
个分类器
- 预测时,投票决定(哪个类赢的次数最多)
✅ 优点:每个分类器只用两个类的数据,更平衡
❌ 缺点:计算开销大(类别多时分类器数量爆炸)
(3)多分类原生支持(如 Softmax 回归、LDA、决策树等)
- 直接建模多类概率分布:
→ 称为 Softmax 回归,是逻辑回归的多类扩展
✅ 2. 如何选择?
| 方法 | 适用场景 |
|---|---|
| OvR | 类别不多,追求效率 |
| OvO | 类别少,追求精度(如 SVM) |
| Softmax/LDA | 数据满足分布假设,追求概率输出 |
📘 5. 类别不平衡问题(Class Imbalance)
现实中很常见:如欺诈检测(99.9%正常,0.1%欺诈)、罕见病诊断等。
✅ 1. 问题表现
- 模型倾向于“总是预测多数类”,Accuracy 虚高
- 少数类 Recall 极低(漏诊严重)
- 评估指标失效(不能只看 Accuracy)
✅ 2. 解决方案
▶︎ 评估指标调整
- 使用 Precision, Recall, F1, AUC, PR曲线 替代 Accuracy
- 对少数类特别关注 → 用 F2(重视 Recall)
▶︎ 数据层面:重采样
(1)过采样(Oversampling)少数类
- 随机复制少数类样本
使用 SMOTE(合成新样本):
→ 在少数类样本之间插值生成“人造样本”
(2)欠采样(Undersampling)多数类
- 随机删除多数类样本
- 使用 Tomek Links / NearMiss 等智能方法
⚠️ 缺点:可能丢失重要信息
▶︎ 算法层面:代价敏感学习(Cost-sensitive Learning)
- 为不同类别设置不同“误分类代价”
- 例如:将少数类分错的代价设为 10 倍
▶︎ 阈值移动(Threshold Moving)
- 默认阈值是 0.5,但对不平衡数据不合适
- 可根据 Precision-Recall 权衡调整阈值
✅ 6. 推荐流程(实战)
- 先用原始数据训练,看混淆矩阵和 F1/AUC
- 尝试 class_weight=’balanced’
- 尝试 SMOTE 过采样
- 调整分类阈值
- 使用 PR 曲线/AUC-PR 评估(比 ROC-AUC 更敏感于不平衡)
📌 AUC-PR(Precision-Recall AUC) 在不平衡数据中比 ROC-AUC 更具参考价值!
🧩 总结对比表
| 方法 | 类型 | 是否概率输出 | 是否支持多分类 | 适合不平衡数据? | 备注 |
|---|---|---|---|---|---|
| 逻辑回归 | 分类 | ✅ | ✅(Softmax/OvR) | ⚠️ 需调整 | 最常用 baseline |
| LDA | 分类+降维 | ✅(后验概率) | ✅ 原生 | ⚠️ 假设高斯分布 | 小样本表现好 |
| OvR / OvO | 多分类策略 | 依赖基分类器 | ✅ | ⚠️ 需配合重采样 | 扩展二分类器 |
| SMOTE | 重采样 | — | — | ✅ | 推荐用于过采样 |
| 代价敏感学习 | 算法调整 | ✅ | ✅ | ✅ | class_weight 最简单有效 |

