机器学习理论(2)
此部分包括决策树 , 神经网络, 支持向量机
今天感觉机器学习这部分只需要理解概念即可, 不需要推公式, 感觉不做理论, 没必要纠结那么深刻, 知道怎么用库实现代码就可以了. 或者对着 gpt 复现一下代码.
🌳 决策树(Decision Tree)
决策树是一种树形结构的分类与回归模型,通过一系列“if-else”规则对样本进行划分,最终在叶节点给出预测结果。因其可解释性强、无需数据预处理、天然支持多分类,被广泛用于工业界和教学中。
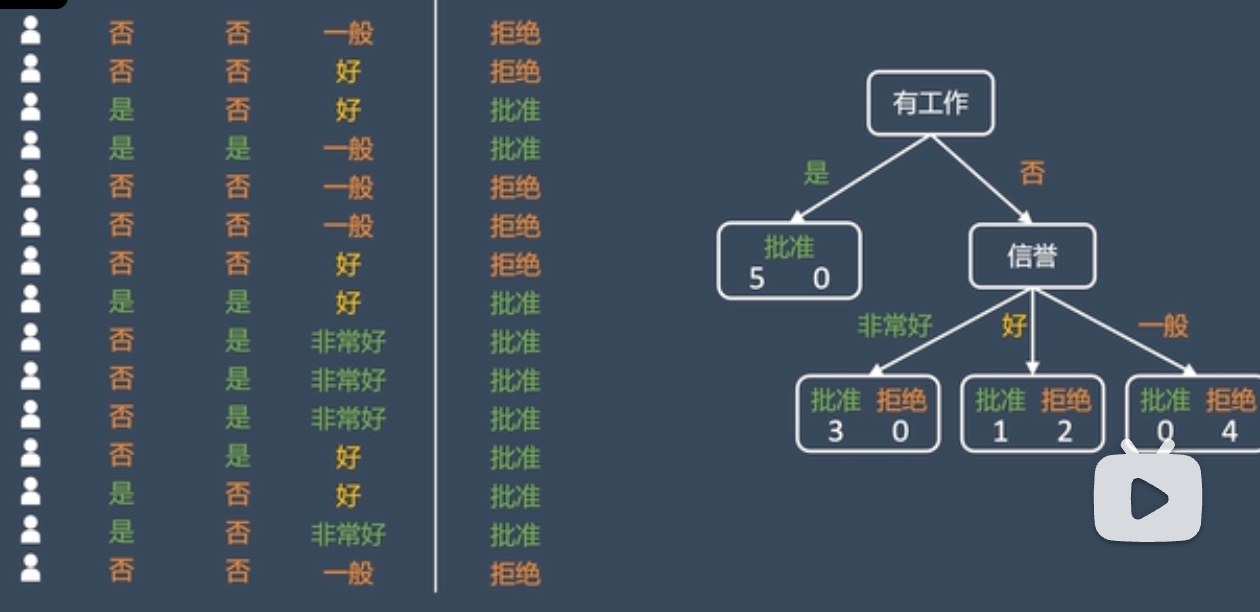
✅ 一、基本结构与流程
1. 组成要素
- 根节点(Root Node):包含全部样本,无入边,有出边
- 内部节点(Internal Node):对应一个特征测试,根据结果分支
- 叶节点(Leaf Node):代表一个类别(分类)或数值(回归),无出边
- 分支(Branch):代表一个判断结果(如“年龄 > 30”)
2. 构建流程(递归分治)
- 从根节点开始,包含所有训练样本
- 选择“最优划分特征”和“划分点”
- 根据划分结果生成子节点
- 对每个子节点递归执行步骤 2~3,直到满足停止条件
- 叶节点赋值(多数类 / 平均值)
✅ 二、划分选择标准(核心公式)
决策树的关键是:如何选择“最优划分”?
常用标准:
1. 信息增益(ID3 算法)—— 分类任务
基于信息熵(Entropy)
(1)信息熵(度量集合纯度):
集合 $D$ 中有 $K$ 个类别:
其中 $p_k$ 是第 $k$ 类样本在 $D$ 中的比例。
→ 熵越小,纯度越高(理想:0,表示全属同一类)
(2)信息增益:
用特征 $a$ 对 $D$ 划分,产生 $V$ 个分支节点(如“是/否” → V=2)
→ 选择使 Gain 最大 的特征进行划分
📌 缺点:偏好取值较多的特征(如“学号”、“ID”)
2. 增益率(C4.5 算法)—— 改进信息增益
引入固有值(Intrinsic Value) 惩罚多分支特征:
其中:
→ 选择 Gain_ratio 最大 的特征
📌 实际中,C4.5 先从候选特征中选出 Gain 高于平均的,再从中选 Gain_ratio 最高的,避免过度惩罚
3. 基尼指数(CART 算法)—— 分类 & 回归树
基尼值反映“从数据集中随机抽取两个样本,其类别不一致的概率”
(1)基尼值:
→ 值越小,纯度越高
(2)基尼指数(用于划分选择):
→ 选择使 Gini_index 最小 的特征和划分点
📌 CART 是二叉树(每个节点只分两支),支持连续值划分(如“年龄 ≤ 30”)
4. 回归树的划分标准(CART)
对于回归任务,使用平方误差最小化:
设节点样本集合为 $D$,预测值为 $c$(常取均值),则:
划分后:
→ 选择使总误差最小的特征和划分点
✅ 三、停止条件(防止过拟合)
递归停止条件包括:
- 当前节点包含样本全属同一类(分类)或方差极小(回归)
- 没有更多特征可用于划分
- 当前节点样本数 < 阈值(如 min_samples_split)
- 树深度达到预设最大值(max_depth)
- 划分后信息增益 / 基尼下降 < 阈值
✅ 四、剪枝(Pruning)—— 防止过拟合
1. 预剪枝(Pre-pruning)
在构建树的过程中提前停止(如设 max_depth、min_samples_leaf)
→ 快速,但可能“欠拟合”
2. 后剪枝(Post-pruning)
先生成完整树,再自底向上剪枝(如 C4.5 的悲观剪枝、CART 的代价复杂度剪枝)
代价复杂度剪枝(CART):
定义损失函数:
- $|T|$:叶节点个数
- $N_t$:叶节点 $t$ 的样本数
- $H_t(T)$:节点 $t$ 的不纯度(如 Gini 或 MSE)
- $\alpha$:复杂度惩罚参数(越大,树越简单)
→ 对每个 $\alpha$ 得到一棵最优子树,通过交叉验证选最佳 $\alpha$
✅ 五、伪代码实现
▶︎ 决策树构建(分类,基于信息增益)
def build_tree(D, features):
if stopping_condition(D): # 如:纯节点、无特征、样本太少
return create_leaf(D) # 返回多数类
best_feature, best_split = None, None
max_gain = -inf
for feature in features:
for split_point in get_possible_splits(D, feature):
gain = calculate_gain(D, feature, split_point)
if gain > max_gain:
max_gain = gain
best_feature = feature
best_split = split_point
if max_gain < threshold:
return create_leaf(D)
node = create_internal_node(best_feature, best_split)
D_left, D_right = split_data(D, best_feature, best_split)
node.left = build_tree(D_left, features)
node.right = build_tree(D_right, features)
return node🧠 神经网络(Neural Networks)
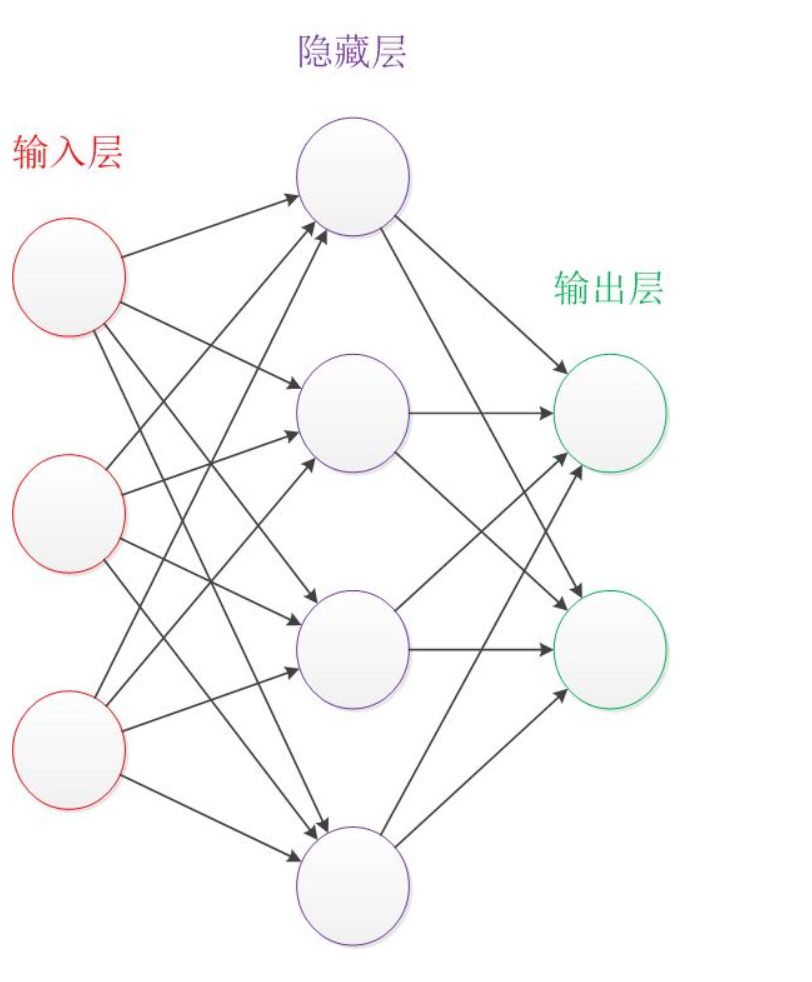
神经网络是一种模拟人脑神经元结构的计算模型,通过多层非线性变换从数据中自动学习特征表示,是深度学习的基础。广泛应用于图像识别、自然语言处理、推荐系统等领域。
✅ 一、基本结构
1. 神经元(Neuron)
每个神经元接收输入,加权求和,加上偏置,再通过激活函数输出:
- $\mathbf{x}$:输入向量
- $\mathbf{w}$:权重向量
- $b$:偏置(bias)
- $f(\cdot)$:激活函数(非线性)
2. 网络结构
- 输入层:接收原始特征
- 隐藏层(可多层):学习特征表示
- 输出层:输出预测结果(如类别概率、回归值)
→ 层数 ≥ 2(输入+输出)即为“多层感知机(MLP)”,≥3 层常称“深度神经网络”
✅ 二、前向传播(Forward Propagation)
逐层计算每一层的输出:
设第 $l$ 层有 $n_l$ 个神经元,输入为 $\mathbf{a}^{[l-1]}$,输出为 $\mathbf{a}^{[l]}$:
- $\mathbf{W}^{[l]}$:第 $l$ 层权重矩阵(维度:$n_l \times n_{l-1}$)
- $\mathbf{b}^{[l]}$:第 $l$ 层偏置向量(维度:$n_l \times 1$)
- $f^{[l]}$:第 $l$ 层激活函数
📌 输出层激活函数根据任务选择:
- 二分类:Sigmoid
- 多分类:Softmax
- 回归:Linear(无激活 或 ReLU)
✅ 三、激活函数(Activation Functions)
引入非线性,使网络能拟合复杂函数。
1. Sigmoid(用于二分类输出层)
→ 输出 ∈ (0,1),可解释为概率
⚠️ 缺点:梯度消失、输出不以0为中心
2. Tanh(双曲正切)
→ 输出 ∈ (-1,1),零中心,但仍有梯度消失
3. ReLU(Rectified Linear Unit,最常用)
✅ 优点:计算快、缓解梯度消失
⚠️ 缺点:Dead ReLU(负值恒为0)
4. Leaky ReLU(改进 ReLU)
→ 避免神经元“死亡”
5. Softmax(用于多分类输出层)
对输出向量 $\mathbf{z} = [z_1, …, z_K]^T$:
→ 输出为概率分布,和为1
✅ 四、损失函数(Loss Function)
衡量预测值与真实值的差距。
1. 均方误差(MSE,回归任务)
2. 交叉熵损失(分类任务)
(1)二分类(Sigmoid 输出)
(2)多分类(Softmax 输出)
其中 $y_{ik}$ 是样本 $i$ 在类别 $k$ 的真实标签(one-hot),$\hat{y}_{ik}$ 是预测概率。
✅ 五、反向传播(Backpropagation)
通过链式法则计算损失对每个参数的梯度,用于更新权重。
核心思想:
- 前向传播计算输出和损失
- 从输出层向输入层逐层计算梯度(误差反向传播)
- 用梯度下降更新参数:
- $\eta$:学习率(learning rate)
📌 关键:链式法则 + 计算图自动微分(现代框架如 PyTorch/TensorFlow 自动完成)
✅ 六、优化器(Optimizer)
梯度下降的改进版本,加速收敛、避免局部最优。
1. SGD(随机梯度下降)
2. Momentum
引入“速度”变量 $v$,加速方向一致的更新:
3. Adam(最常用)
结合 Momentum + 自适应学习率(RMSProp):
默认参数:$\beta_1=0.9, \beta_2=0.999, \epsilon=10^{-8}$
✅ 七、伪代码(训练流程)
初始化网络参数 W, b
设置超参数:学习率 η,epochs,batch_size
for epoch in range(epochs):
for batch in dataloader:
X_batch, y_batch = batch
# 前向传播
y_pred = forward(X_batch)
# 计算损失
loss = compute_loss(y_pred, y_batch)
# 反向传播(自动微分)
gradients = backward(loss)
# 更新参数(如 Adam)
update_parameters(gradients, η)
# 可选:每轮评估验证集性能
val_loss = evaluate(val_data)🧭 支持向量机(Support Vector Machine, SVM)
支持向量机是一种最大间隔分类器,通过寻找一个“最优超平面”将不同类别的样本分开,具有理论优美、泛化能力强、适合小样本等特点,广泛应用于文本分类、图像识别、生物信息等领域。
✅ 一、基本思想
SVM 的目标是:找到一个超平面,使得两类样本之间的“间隔(margin)”最大化。
- 间隔:两类样本到超平面的最小距离之和
- 支持向量:距离超平面最近的那些样本点,决定超平面位置
- 最大间隔 → 最强泛化能力
📌 通俗理解:不是随便画一条线分开两类,而是画一条“最居中、最宽敞”的线。
✅ 二、线性可分情况:硬间隔 SVM
假设数据线性可分,存在超平面:
使得:
- 对正类样本($y_i = +1$):$\mathbf{w}^T \mathbf{x}_i + b \geq +1$
- 对负类样本($y_i = -1$):$\mathbf{w}^T \mathbf{x}_i + b \leq -1$
→ 合并为:
1. 间隔计算
样本点 $\mathbf{x}_i$ 到超平面的距离:
支持向量满足 $y_i (\mathbf{w}^T \mathbf{x}_i + b) = 1$,所以间隔为:
→ 最大化间隔 = 最小化 $|\mathbf{w}|$
2. 优化问题(硬间隔)
→ 凸二次规划问题,可求全局最优解
✅ 三、线性不可分情况:软间隔 SVM
现实数据常含噪声或轻微重叠,硬间隔无法满足 → 引入松弛变量 $\xi_i \geq 0$,允许部分样本违反约束。
优化问题(软间隔)
- $\xi_i$:第 $i$ 个样本的“容错量”
- $C$:惩罚参数(正则化系数)
- $C$ 大 → 强调分类准确,间隔小,易过拟合
- $C$ 小 → 允许更多误分类,间隔大,泛化强
✅ 四、对偶问题与支持向量
通过拉格朗日乘子法,将原始问题转化为对偶问题,便于求解和引入核函数。
拉格朗日函数:
对偶问题(软间隔):
→ 求解 $\alpha_i$(拉格朗日乘子)
📌 支持向量:$\alpha_i > 0$ 的样本点
→ 只有支持向量参与最终决策,其余样本被“忽略”
决策函数:
✅ 五、核技巧(Kernel Trick)—— 处理非线性问题
当数据线性不可分时,可通过非线性映射 $\phi(\mathbf{x})$ 将数据映射到高维空间,使其线性可分。
但直接计算 $\phi(\mathbf{x})$ 可能维度爆炸 → 核函数避免显式计算:
定义核函数:
→ 在对偶问题中,只需计算核函数,无需知道 $\phi$
常用核函数:
1. 线性核(Linear)
→ 等价于原始 SVM,适合线性可分数据
2. 多项式核(Polynomial)
- $\gamma > 0$,$r \geq 0$,$d$ 为次数
3. 高斯核 / RBF 核(最常用)
- $\gamma > 0$,控制“影响半径”
- 适合复杂非线性边界
4. Sigmoid 核(类似神经网络)
→ 理论上不总是有效核(可能不满足 Mercer 条件)
✅ 六、伪代码(训练流程)
输入:训练集 {(x1, y1), ..., (xn, yn)}, 核函数 K, 惩罚系数 C
步骤1:构造对偶优化问题(使用核函数)
max α: Σαi - 1/2 ΣΣ αi αj yi yj K(xi, xj)
s.t. 0 ≤ αi ≤ C, Σαi yi = 0
步骤2:使用 SMO(序列最小优化)等算法求解 α
步骤3:计算 b(使用支持向量,即 αi > 0 的样本)
选一个 0 < αk < C 的样本 xk(确保在间隔边界上)
b = yk - Σ αi yi K(xi, xk)
步骤4:构建决策函数
f(x) = sign( Σ αi yi K(xi, x) + b )
输出:支持向量集合、α、b、决策函数 f(x)
