Modern Agent [1] Survey
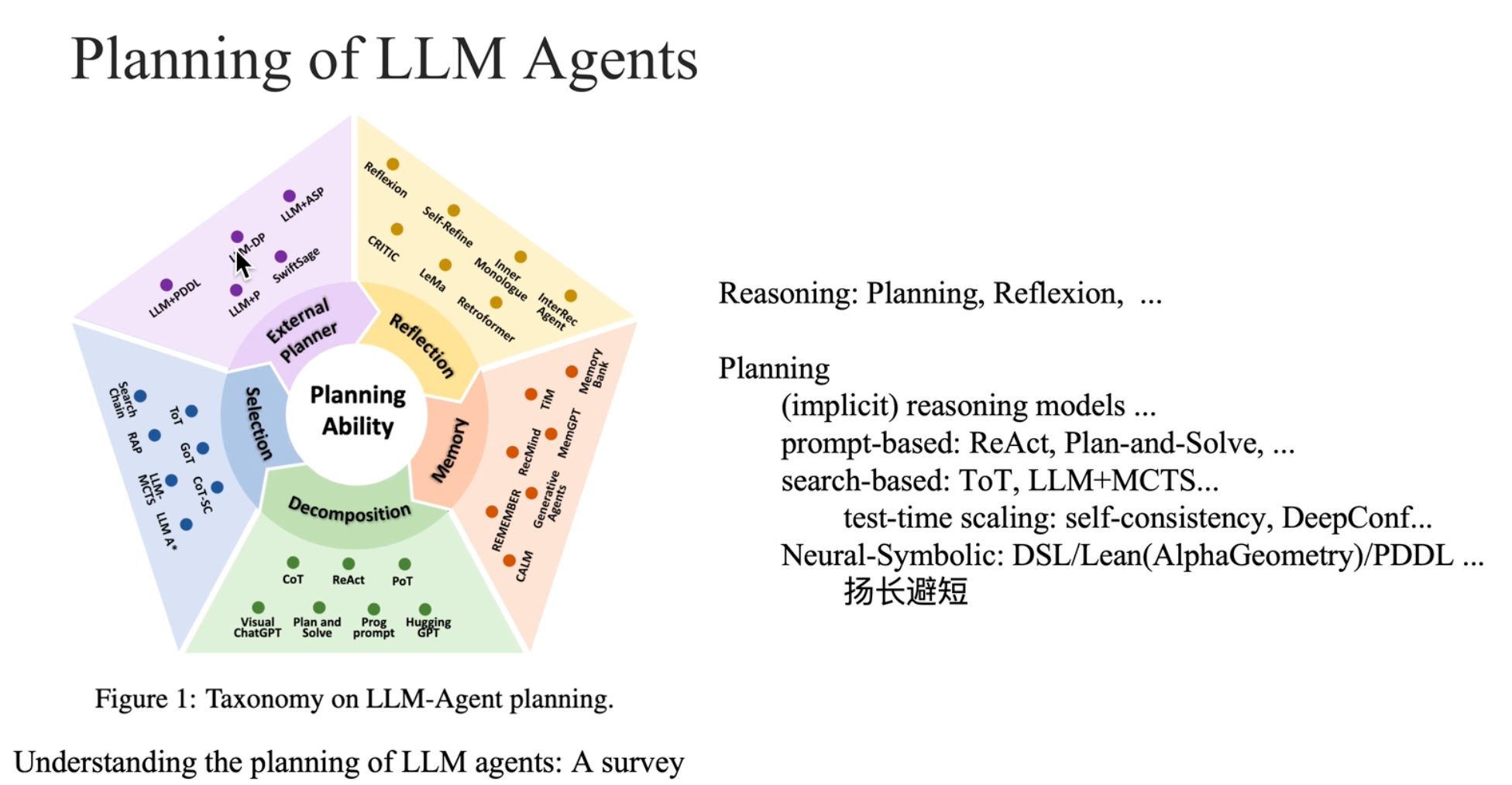
基础:推理(Reasoning)与规划(Planning)
核心定义
- 推理:从有限已知前提(如 “所有人会死”“苏格拉底是人”)推导出深层结论(“苏格拉底会死”),是 Agent 智能的核心体现,也是规划、反思的基础。
- 规划:以推理为前提,对复杂任务进行 “目标识别→步骤分解→分步执行”,解决 LLM 在长周期、多轮交互任务中的短板。
- Agentic 特性:模型通过与外部环境交互式解决问题,推理能力的强弱决定了对 Agent 智能的评价(超预期→惊艳,浅层次→失望)。
经典推理类型
| 类型 | 逻辑特点 | 例子 |
|---|---|---|
| 演绎推理 | 确定性、前向推 | 三段论(大前提→小前提→结论) |
| 归纳推理 | 或然性、多前提 | 见过的天鹅都是白色→天鹅皆白 |
LLM 原生短板(规划必要性)
- 直接生成规划易出错(如积木堆叠任务中步骤遗漏 / 违规);
- 长上下文迷失(多轮交互后忘记目标 / 已执行动作);
- 无法处理精密状态约束(如机械臂一次只能拿一个物体)。
模块 1:任务分解(最基础)
核心目标:将复杂任务拆成小步骤,降低 LLM 推理难度
- 关键方法
| 方法 | 核心逻辑 | 适用场景 |
|---|---|---|
| CoT(思维链) | Let’s think step by step,分步推理 | 简单逻辑题、短流程任务 |
| ReAct | 思考→行动→观察→再思考(边交互边拆) | 需调用工具 / 环境反馈的任务 |
| Plan-and-Solve | 先显式生成完整规划,再严格执行 | 长周期、多步骤复杂任务 |
优势与改进
比 LLM 直接出答案准确率高,Plan-so 比 CoT 提升约 10 个点;
动态优化:引入环境反馈,支持 “执行→修正规划”(弥补 “缸中之脑” 与真实交互的差距)。
模块 2:路径选择(解决 “多分支、状态爆炸”)
- 核心目标:LLM 生成多个解题思路时,筛选最优路径,避免无效探索
- 核心方案
| 方案 | 核心逻辑 | 关键技术 |
|---|---|---|
| ToT(思维树) | 思考过程拆成树结构,择优拓展节点 | 节点打分、剪枝(淘汰差路径) |
| LATS(LLM+MCTS) | 结合蒙特卡洛树搜索,引导思考方向 | UCB 值(平衡探索与利用) |
模块 3:外部求解器(神经符号方案,工程落地重点)
核心思路:扬长避短 ——LLM 做 “理解 / 翻译”,专业工具做 “精密规划”
代表工具:PDDL(规划领域标准语言)
经典流程(LM+P 方案)
- LLM 输入:自然语言任务(如 “把笔记本放进抽屉”);
- LLM 输出:目标状态(如 “笔记本 1 在抽屉 1 内”);
- PDDL 求解器:基于目标状态 + 环境约束(如 “一次只能拿一个物体”),生成可执行步骤;
- LLM 翻译:将 PDDL 步骤转为自然语言 / 执行指令。
优势:解决 LLM 直接规划的 “步骤错误、约束违反” 问题,稳定性拉满。
核心考点:什么是神经符号方案?LLM+PDDL 的工作流程?
模块 4:反思(Reflection/Self-Critic)
核心定义
- Agent 在生成方案、执行步骤后,对自身行为 / 结果进行 “自我批评、错误识别、优化修正” 的闭环过程,是提升规划可靠性、减少重复犯错的关键。
本质:让 Agent 具备 “元认知能力”—— 不仅能解决问题,还能监控解决问题的过程。
核心价值
- 弥补 LLM “一次性输出” 的缺陷:解决 “生成即结束” 导致的错误无法修正问题;
- 提升复杂任务成功率:通过多轮迭代优化,让方案更贴合目标和约束;
- 降低外部依赖:减少对人工干预的需求,让 Agent 更自主。
经典实现方法与案例
| 方法 / 案例 | 核心逻辑 | 适用场景 |
|---|---|---|
| Self-Critic(自我批判) | 先生成候选方案 → 调用 LLM 作为 “批判者”,检查逻辑漏洞 / 步骤错误 → 基于批判结果修正方案 | 逻辑推理、数学解题、规划生成 |
| UCLA IMO 解决方案 | 提议(Generate Proposal)→ 验证(Verification)→ 反思(Reflection)→ 迭代完善(Iterate),循环至满足条件 | 高难度逻辑题、竞赛类任务 |
| Deep Conf | 计算每个 token 的置信度 → 加权得到整体方案置信度 → 对低置信度部分重点反思修正 | 事实性任务、精确计算类任务 |
关键设计要点
- 反思触发条件:执行失败后、方案置信度低于阈值、多轮交互后偏离目标;
- 反思 Prompt 设计:明确要求 LLM“指出具体错误 + 给出修正方向”,而非泛泛评价;
- 迭代次数控制:避免无限循环,设定最大迭代次数(如 3-5 轮)。
核心考点:反思在 Agent 中的作用?经典的 “生成 - 验证 - 反思” 工作流是什么?
模块 5:记忆(Memory)
核心定义: Agent 对 “历史信息” 的存储与调用系统,包括事实数据、执行记录、反思结论等,是支撑长周期任务、深度推理的基础 —— 无记忆则无持续智能。
核心区别:Agent 的记忆≠简单存储,而是 “有选择、有提炼、能复用” 的信息管理。
记忆的分类与层级
| 记忆类型 | 存储内容 | 特点 | 作用 |
|---|---|---|---|
| 短时记忆(Working Memory) | 当前任务的目标、已执行步骤、实时环境反馈 | 临时存储、容量有限 | 支撑单轮 / 短流程任务执行 |
| 长时记忆(Long-Term Memory) | 历史任务的经验、反思结论、通用规则(如 “机械臂一次只能拿一个物体”) | 持久存储、可复用 | 指导新任务规划、避免重复犯错 |
| 深层记忆(Reflective Memory) | 从多个事实 / 经验中提炼的抽象结论(如 “多次在步骤 3 出错→需先检查状态约束”) | 抽象化、规律化 | 提升规划效率和准确性 |
记忆设计的核心原则
- 与反思强绑定:单纯记录事实的 “浅层记忆” 无价值,需结合反思提炼深层结论(如 “记录‘上午读论文’→ 反思‘对科研有热情’→ 指导‘推荐科研相关任务’”);
- 动态更新:根据新任务反馈、反思结果,持续更新长时记忆(新增有效经验、删除无效信息);
- 高效检索:通过关键词、任务类型等索引,让 Agent 在规划时快速调用相关记忆(避免长上下文冗余)。
经典应用场景
- 长周期任务:如持续 1 周的项目管理,Agent 通过记忆记录每日进度、问题,指导次日规划;
- 个性化交互:记忆用户偏好(如 “不喜欢复杂步骤”),生成适配的规划方案;
- 错误规避:记忆 “之前步骤 5 违反状态约束→本次规划直接跳过无效路径”。
核心考点:Agent 的记忆为什么需要结合反思?短时记忆与长时记忆的区别及作用?
![Modern Agent [02] LangChain & LangGraph 实现 ReAct](https://zzhaire-markdown.oss-cn-shanghai.aliyuncs.com/imgs/image-20260320205630675.png)
