Modern Agent [3] Gemini 2.5 pro Workflow
核心成果
仅使用原生 Gemini 2.5 Pro(无微调),搭配「生成 - 验证 - 修正」迭代 Agent 工作流,解出 2025 IMO 6 道题中的前 5 道,达到人类 IMO 金牌水平;单独调用 API 无法实现该效果。
整体核心思路
采用 Actor-Critic 模式:
Actor:Gemini 充当解题生成器
Critic:Gemini 同时充当竞赛级阅卷验证器
通过多轮迭代,不断完善解法直至合格。
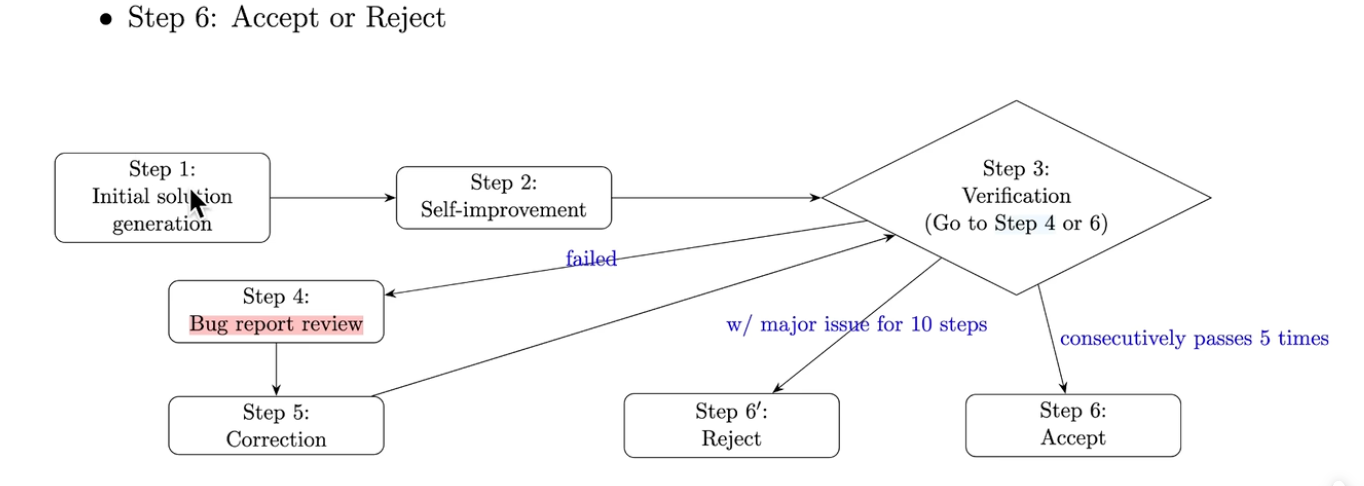
完整工作流步骤
1. 初始解生成(Step 1 + Step 2)
Step 1
输入题目 + 解题 Prompt,模型生成初始解;但因 Thinking Token 上限(32768)易被打满,解法仓促、逻辑不完整。
Step 2
共享 Step 1 上下文,追加改进 Prompt,让模型继续思考、补全步骤、修正疏漏,充分利用思考能力,最终得到
完整初始解
。
2. 解法验证(Step 3)
角色定位:IMO 级别数学家 + 严谨阅卷人
工作规则:只验证、不修正,逐步骤检查
错误类型:
① 严重逻辑错误
② 证明跳步(Justification Gap)
输出内容:验证结论(有效 / 无效)+ Bug 报告(错误位置 + 原因)+ 详细验证日志
3. 解法修正(Step 4)
输入:当前解法 + 验证得到的 Bug Report
模型根据反馈修改错误、填补逻辑缺口,生成新的解法
4. 循环迭代
新解法重新送入「验证环节」,不断重复「验证→修正→验证」,直到满足终止条件。
终止判断规则
- 成功终止:连续 5 次验证均判定无瑕疵、解法有效 → 接受该答案
- 失败终止:连续 10 次验证均不通过 → 判定此题无法求解
关键结论
初始解质量决定最终成败
初始解与正确解重叠度高 → 易修正成功;初始解方向错误 → 基本无法挽回。
迭代循环是关键
单纯调用模型无法解出难题,生成 - 评估 - 修正的流程能充分激发模型能力。
模型通用性强
Gemini 2.5 Pro 可同时胜任「解题生成」和「严谨验证」两个角色。
Prompt 设计要点
解题 Prompt(生成解)
- 格式:标准 Markdown 结构化
- 核心要求:逻辑严谨、禁止幻觉(不会不硬编)
- 输出结构:总结(结论 + 解题思路)+ 详细解题步骤,方便后续提取与判断。
验证 Prompt
- 角色扮演:顶级数学竞赛阅卷者
- 约束:只做审查,不提供修正方案
- 输出:结构化结论 + 问题清单,用于后续修正环节。
工程实现细节
- 原生 HTTP/Post 请求易超时(思考耗时近 10 分钟),改用 Google GenAI SDK + 流式输出 更稳定,可实时监控过程。
- 模型展示的 Thinking 过程是总结版,并非原生思考流。
- Thinking Token 预算控制不严格,设置 32768 实际可能超 34000。
实际运行案例(IMO 第 1 题)
- 外部大循环仅运行 1 次
- 内部迭代共 8 轮
- 前几轮验证失败并持续修正,第 4 轮后验证通过,随后连续 5 次合格,满足成功条件。
![Modern Agent [02] LangChain & LangGraph 实现 ReAct](https://zzhaire-markdown.oss-cn-shanghai.aliyuncs.com/imgs/image-20260320205630675.png)