NetLLM 论文阅读笔记 (1)
Chapter 1: Introduction
研究背景:网络算法演进
Rule-Based → DL-Based → LLM-Based| 范式 | 代表工作 | 核心特点 | 主要局限 |
|---|---|---|---|
| Rule-Based | Copa, PANDA | 人工设计控制规则 | 规则工程成本高,适应性弱 |
| DL-Based | Pensieve, Decima | 任务专用DNN,自动策略发现 | 一任务一模型,泛化能力差 |
| LLM-Based (NetLLM) | 本文 | 基础模型适配,一模型多任务 | 需解决模态/效率/成本挑战 |
现有学习式方法的两大局限
🔹 高模型工程成本 (High Model Engineering Costs)
- DNN架构设计对性能至关重要,但难以手工优化
- 不同任务需专用模型,无法共享参数
- 即使引入Transformer,仍需调参/设计tokenization scheme
🔹 泛化能力弱 (Low Generalization)
- 在未见数据分布/网络环境下性能下降
- 例:平滑网络训练的ABR模型 → 动态带宽场景失效
- 阻碍学习式算法在实际生产环境中的部署
LLM带来的新机遇
✨ LLM核心优势
- 预训练知识丰富:海量语料学习通用模式
- 涌现能力:planning, pattern mining, problem solving, generalization
- 跨域迁移潜力:robotics[23], chip design[59], protein prediction[55] 已验证
🎯 核心研究问题
Can one LLM efficiently and effectively solve multiple networking tasks?💡 Key Insight: “From model engineering → foundation model adaptation”
本文贡献
挑战识别:系统识别LLM适配网络的三大挑战,验证Prompt Learning等自然替代方案效果次优(§3)
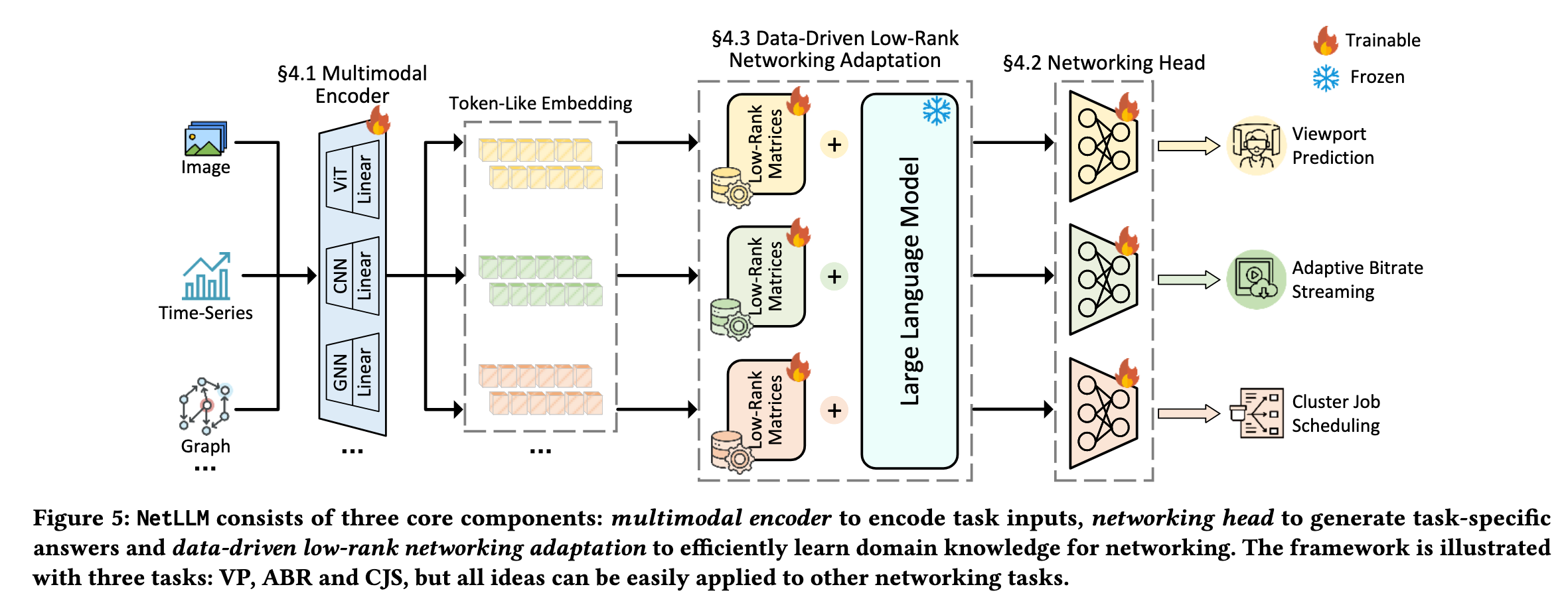
框架设计:提出NetLLM,首个LLM网络适配框架,含三核心模块(§4):
- Multimodal Encoder:多模态输入编码
- Networking Head:高效可靠答案生成
- DD-LRNA:数据驱动+低秩微调,降低适配成本
实验验证:三个任务上验证有效性(§5):
- VP: MAE↓ 10.1-36.6%
- ABR: QoE↑ 14.5-36.6%
- CJS: JCT↓ 6.8-41.3%
- 泛化能力:未见环境下仍保持优势
Chapter 2: Background
学习式网络算法
🔹 两大学习范式
| 范式 | 适用任务 | 代表工作 | 训练方式 |
|---|---|---|---|
| Supervised Learning | 预测类:流量分类、带宽预测、视口预测 | [54,73,64,85] | 标注数据 + 损失函数优化 |
| Reinforcement Learning | 决策类:拥塞控制、ABR、CJS | [1,106,44,62,63] | 环境交互 + 奖励优化 |
🔹 核心局限
- 模型工程成本高:不同任务需专用DNN架构,无法共享
- 泛化能力弱:在未见数据分布/网络环境下性能下降
📌 Figure suggestion: 可添加学习范式对比流程图
LLM 基础机制
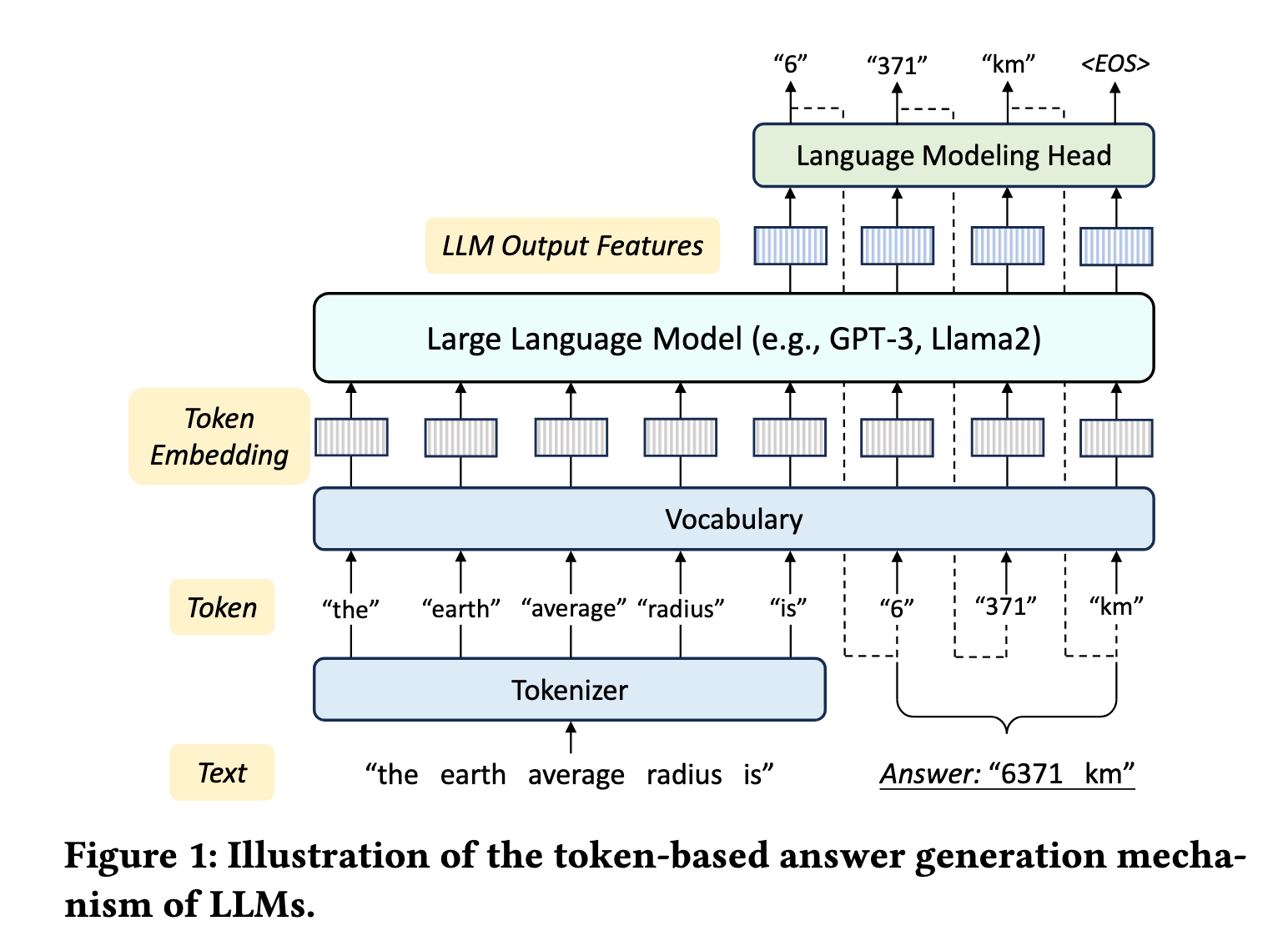
🔹 答案生成流程(Fig 1)
输入文本 → Tokenizer分词 → Vocabulary映射embedding
→ LLM编码 → LM Head逐token预测 → 输出文本🔹 三大核心组件
| 组件 | 功能 | 关键特性 |
|---|---|---|
| Tokenizer | 将文本切分为token序列 | 子词切分(如”awesome”→“aw”+“esome”) |
| Vocabulary | 映射token→embedding向量 | 固定维度,可被LLM处理 |
| LM Head | 预测下一个token的概率分布 | Autoregressive生成,需多轮推理 |
🔹 关键约束
- 原生输入:仅支持纯文本模态
- 生成方式:逐token预测,延迟高,可能产生幻觉
评估任务概览
| 任务 | 输入模态 | 输出 | 目标 | 学习范式 |
|---|---|---|---|---|
| VP (Viewport Prediction) | 时序(历史视口)+图像(显著性图) | 未来视口坐标(roll/pitch/yaw) | 最小化预测误差 | SL |
| ABR (Adaptive Bitrate) | 时序(吞吐量/延迟)+序列(码率)+标量(缓冲) | 下一chunk码率 | 最大化QoE | RL |
| CJS (Cluster Job Scheduling) | 图(DAG依赖)+标量(资源需求) | 下一执行阶段+executor数量 | 最小化平均JCT | RL |
- 覆盖学习范式:SL预测 + RL决策,代表性强
- 覆盖控制模式:集中式控制(CJS) + 分布式控制(ABR)
- 覆盖输入模态:时序/图像/图/标量,考验多模态编码能力
![Modern Agent [3] Gemini 2.5 pro Workflow](https://zzhaire-markdown.oss-cn-shanghai.aliyuncs.com/imgs/image-20260320212730476.png)