NetLLM 论文阅读笔记 (2)
Chapter 3: Motivation & Challenges
三大核心挑战概览
- 🔹 Challenge 1: Large Input Modality Gap
- 网络输入(时序/图/图像/标量)≠ LLM原生文本输入
- 自然方案:Prompt Learning(设计模板将数据转文本)
- 问题:时序模式、拓扑关系难以用文本精准表达
- 🔹 Challenge 2: Inefficiency of Token-Based Answer
Generation
- LM Head逐token预测 → 多轮推理,延迟高(~3.84s/答案)
- 幻觉风险:生成答案可能物理无效(如不存在的码率)
- 网络任务要求高可靠性+快速响应(<1s deadline)
- 🔹 Challenge 3: High Adaptation Costs
- RL任务需与环境交互收集经验,耗时巨大(占训练时间39-52%)
- 全参数微调显存/计算开销大(65.88GB, 7.9h)
- 难以多任务共享同一模型
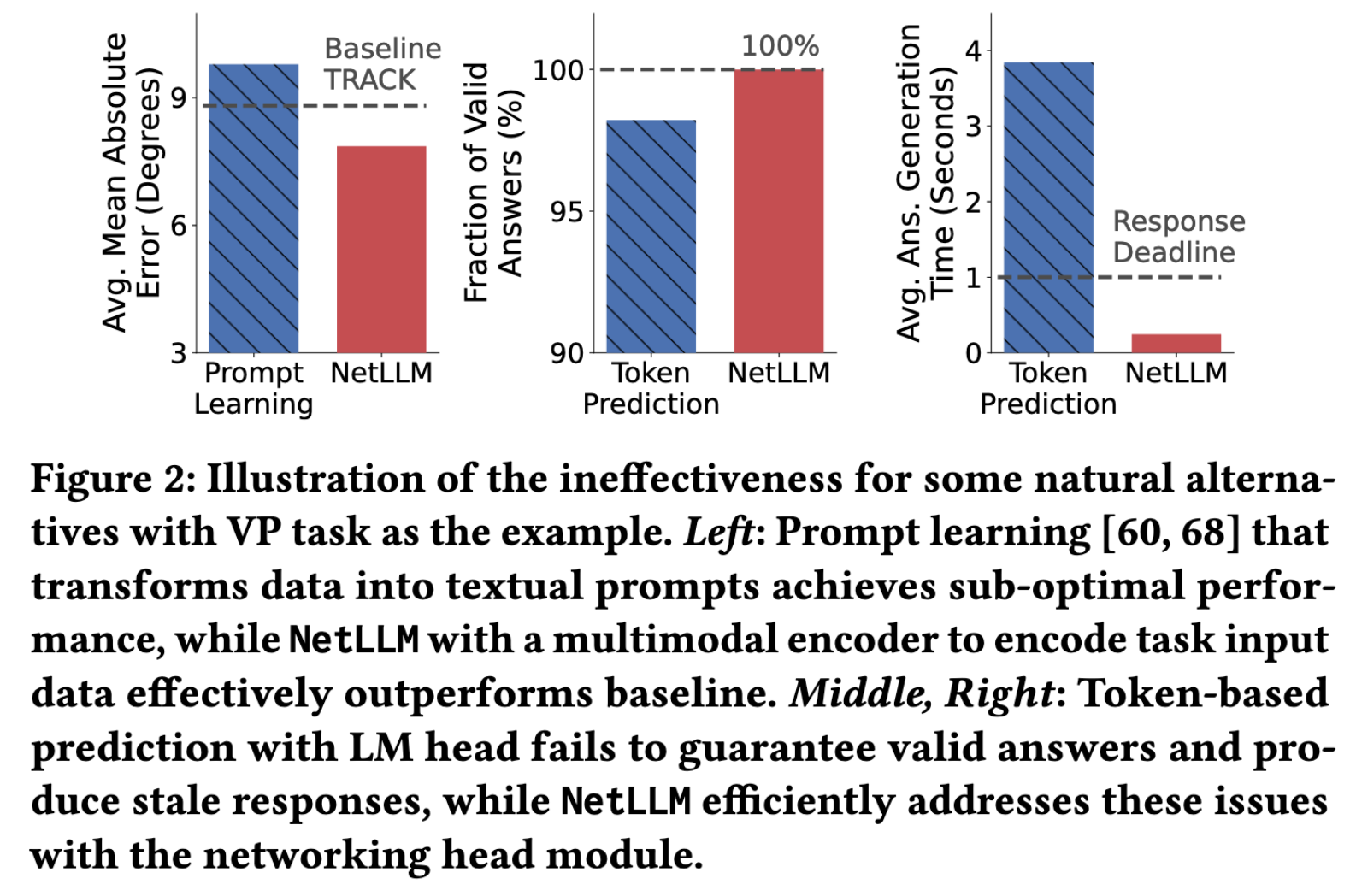
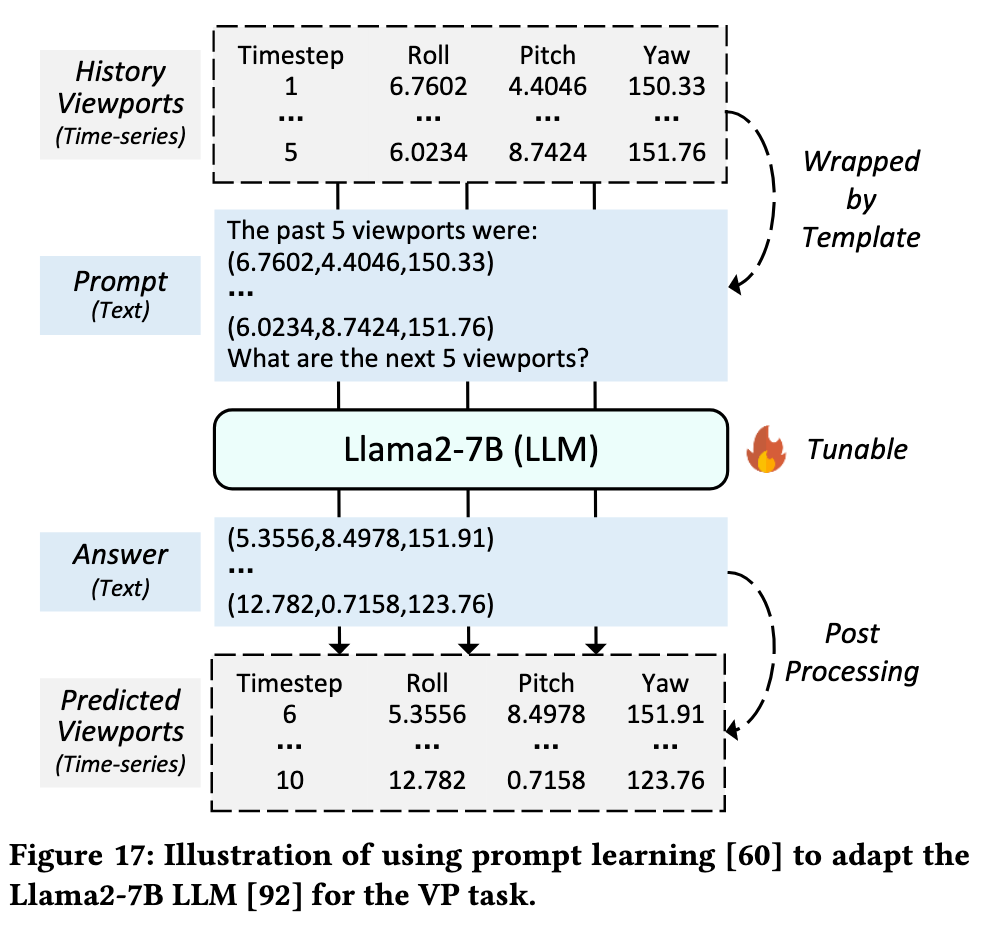
Prompt Learning 为何效果次优?(以VP任务为例)
🔹 实验设置
- 用模板封装历史视口数据 → 文本prompt输入Llama2-7B
- 预测未来1秒视口(5Hz采样,5个时间点)
- 用OpenPrompt微调10万轮
🔹 关键结果(图2左)
| 方法 | MAE (↓) | 相对TRACK |
|---|---|---|
| TRACK (SOTA) | ~9.0° | - |
| Prompt+Llama2 | ~10.0° | +11.1% |
🔹 根本原因
- ❌ 时序数据的时变模式在文本中丢失
- ❌ 复杂模态(图像、DAG)无法直接文本化
- ❌ 需手工设计模板+后处理规则 → 回到”rule engineering”老路
Token生成机制的可靠性与效率问题
🔹 答案有效性(图2中)
- Token预测存在不确定性 → 可能生成非法输出
- VP任务:有效答案比例 < 100%
- 需复杂后处理规则解析 → 工程开销大
🔹 生成延迟(图2右)
- 单答案需多轮推理(子词tokenization)
- VP任务:平均3.84s/答案 > 1s响应deadline
- 无法及时响应网络状态变化
🔹 核心矛盾
- LLM原生设计: NLP对话 → 容忍延迟+幻觉
- 网络任务需求: 高可靠+低延迟+答案空间约束
适配成本:为什么标准微调不可行?
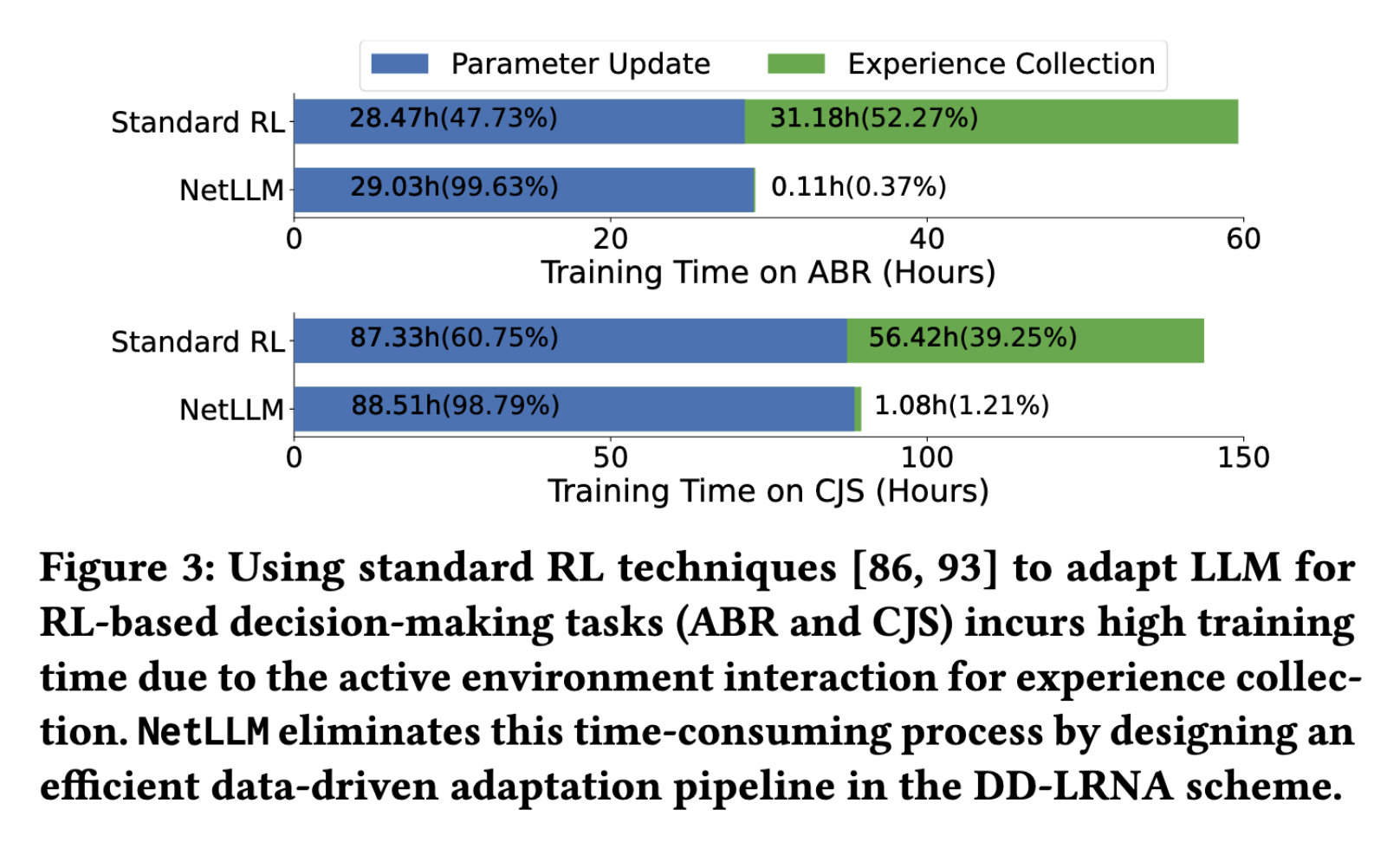
🔹 RL任务交互成本高(图3)
| 任务 | 经验收集耗时 | 占总训练时间 |
|---|---|---|
| ABR | 31.18h | 52.27% |
| CJS | 56.42h | 39.25% |
- LLM参数大 → 单轮推理慢 → 交互收集经验极耗时
- 标准RL需持续交互 → 训练周期难以接受
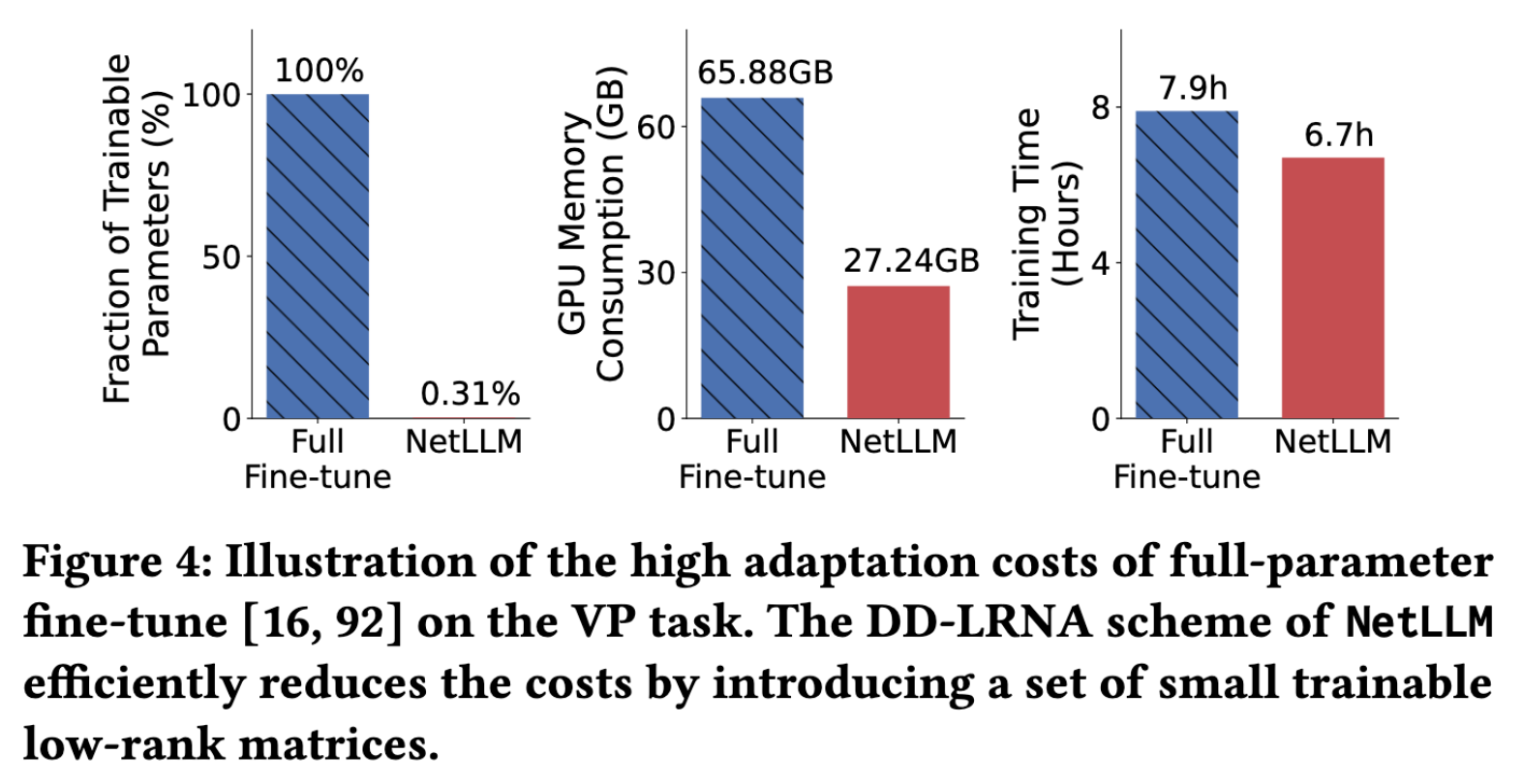
🔹 全参数微调资源消耗大(图4)
| 指标 | 全参数微调 | NetLLM (DD-LRNA) |
|---|---|---|
| 可训练参数 | 100% | 0.31% |
| GPU显存 | 65.88GB | 27.24GB(-60.9%) |
| 训练时间 | 7.9h | 6.7h(-15.1%) |
🔹 知识破坏风险
- 全参数更新可能破坏预训练通用知识
- 难以实现”一模型多任务”共享
📌 Figure suggestion: Figure 3, Figure 4 + 关键数字高亮
Chapter 4: NetLLM Design
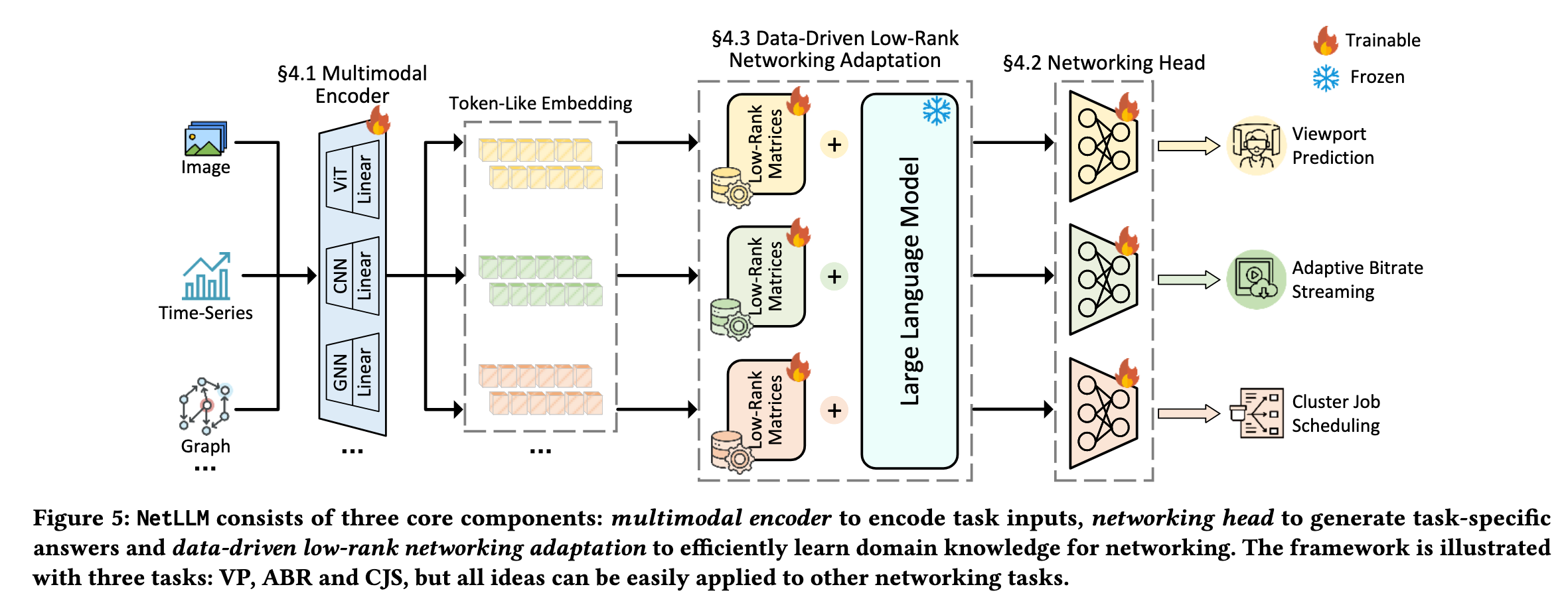
整体架构概览
🔹 核心思想
冻结LLM主干 + 轻量适配模块 → 高效领域知识迁移1🔹 三模块协同(图5)
[多模态输入]
↓
[§4.1 Multimodal Encoder] → 投影到token空间
↓
[Frozen LLM + §4.3 Low-Rank Matrices] → 特征提取+知识迁移
↓
[§4.2 Networking Head] → 单轮直接输出合法答案
↓
[任务答案]🔹 关键特性
| 特性 | 实现机制 | 解决挑战 |
|---|---|---|
| Compatibility | 通用接口,兼容不同LLM/任务 | - |
| Reliability | Networking Head约束答案空间 | Challenge 2 |
| Efficiency | DD-LRNA低秩适配+离线数据驱动 | Challenge 3 |
| Transferability | 冻结主干+任务特定低秩矩阵 | Challenge 1+3 |
模块一:多模态编码器 (Multimodal Encoder)
设计目标
将异构网络输入自动投影到 LLM 的 Token 空间,使 LLM 能“理解”多模态数据。
两阶段架构(图 6)
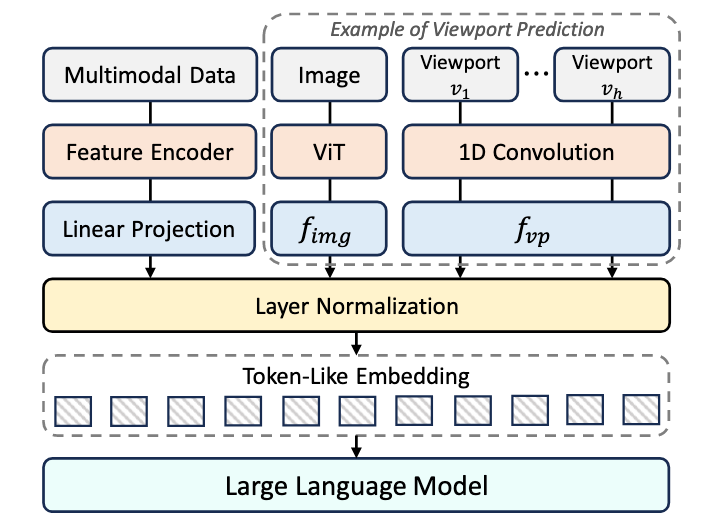
原始输入 → [模态专用 Feature Encoder] → 特征
→ [线性投影层 + LayerNorm] → Token-like Embeddings模态专用 Encoder 复用(避免从零设计)
| 输入模态 | Feature Encoder | 来源/状态 |
|---|---|---|
| 图像 | ViT (Vision Transformer) | [22], 预训练权重冻结 |
| 时序/序列 | 1D-CNN | [62], 可训练 |
| 标量 | Fully Connected (全连接层) | 可训练 |
| 图结构 | GNN (图神经网络) | [63,101], 可训练 |
关键设计细节
- 线性投影层:学习从特征空间到 Token 空间的高效映射(如 ViT 输出 768 维 → Llama2 输入 4096 维)。
- LayerNorm:保证训练稳定性。
- 效果:相比 Prompt Learning,VP 任务 MAE 降低 19.7%。
模块二:网络任务头 (Networking Head)
设计目标
替代原生 LM Head,实现单轮推理 + 答案空间约束,解决幻觉和延迟问题。
核心对比(图 7)
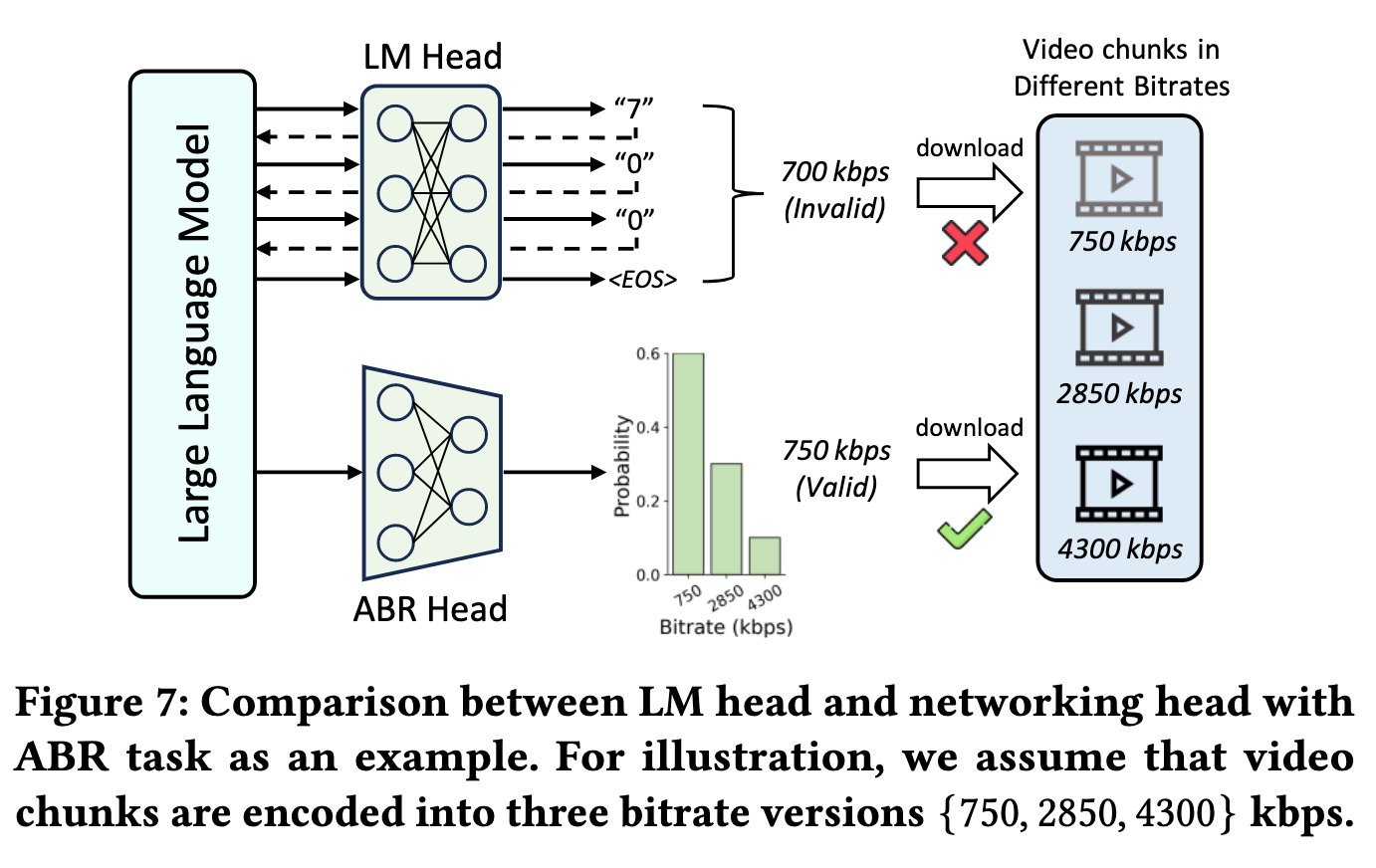
| 特性 | LM Head (原生) | Networking Head (NetLLM) |
|---|---|---|
| 生成方式 | 逐 Token 预测,多轮推理 | 单轮直接输出 |
| 答案空间 | 整个 Vocabulary,可能非法 | 任务合法答案集合,100% 有效 |
| 延迟 | 高 (~3.84 秒/答案) | 低 (~0.1-0.3 秒/答案) |
| 实现 | 复杂 Token 解码 + 后处理 | 轻量线性层,端到端 |
任务定制示例
- VP Head:3 神经元线性层 → 输出 (roll, pitch, yaw) 坐标。
- ABR Head:Softmax 层 → 输出候选码率概率分布。
- CJS Head:双头设计 → (1) 下一执行阶段 (2) Executor 数量。
可靠性保障
答案空间约束:输出 ∈ {合法答案集合}
→ 消除幻觉风险 + 无需后处理 + 满足实时性要求模块三:DD-LRNA (核心创新)
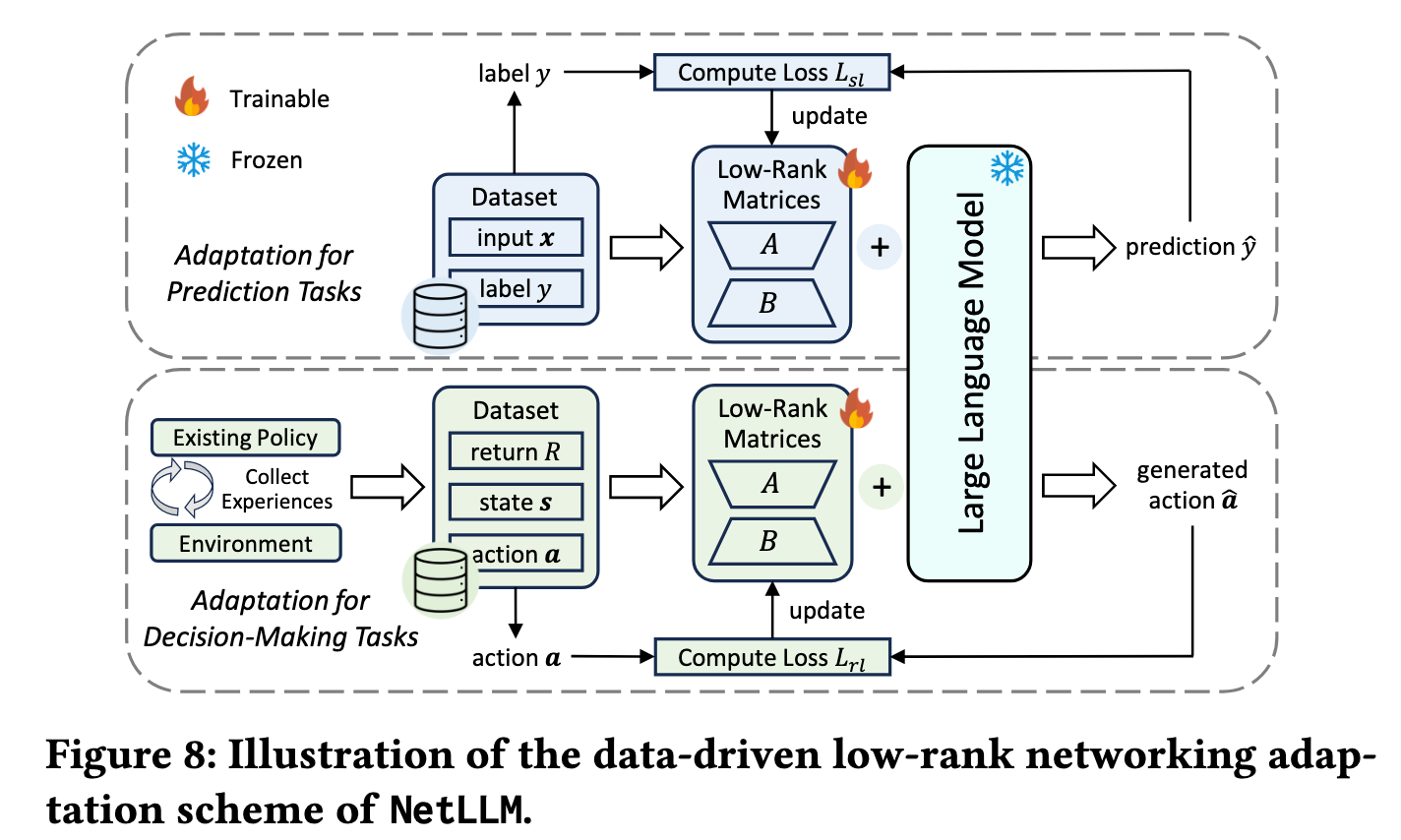
全称 Data-Driven Low-Rank Networking Adaptation (数据驱动低秩网络适配)
子设计 1:数据驱动适配流水线 (Data-Driven Pipeline)
动机:避免训练时与环境实时交互(解决挑战 3)。
流程:
- 离线经验收集(一次性):
- 用现有算法(如 Decima/GENET)与环境交互收集轨迹数据集。
- 数据集:,。
- 序列重构:
- 将 RL 问题转化为序列预测问题(类似 Decision Transformer)。
- 输入:历史状态 + 目标回报 (Target Return)。
- 损失计算:
- 预测动作与真实动作的差异(交叉熵或均方误差)。
- 推理触发:
- 设定目标回报(如最大回报)触发 LLM 生成最优策略动作。
优势:
- 训练过程无需环境交互 → 节省 52%/39% 训练时间(ABR/CJS)。
- 复用现有算法经验 → 快速启动,避免冷启动。
子设计 2:低秩矩阵适配 (Low-Rank Adaptation)
动机:参数更新量具有低秩特性,无需微调全参数。
方法(类 LoRA):
- 冻结预训练权重 。
- 引入低秩矩阵 。
- 权重更新:,。
- 仅训练 + Encoder + Head。
效率收益(图 4):
| 指标 | 全参数微调 | DD-LRNA | 提升 |
|---|---|---|---|
| 可训练参数 | 100% | 0.31% | ↓99.69% |
| GPU 显存 | 65.88GB | 27.24GB | ↓60.9% |
| 训练时间 | 7.9h | 6.7h | ↓15.1% |
额外优势:
- 预训练知识不被破坏 → 泛化能力更强。
- 同一 LLM 基座 + 不同低秩矩阵副本 → 支持多任务共享。