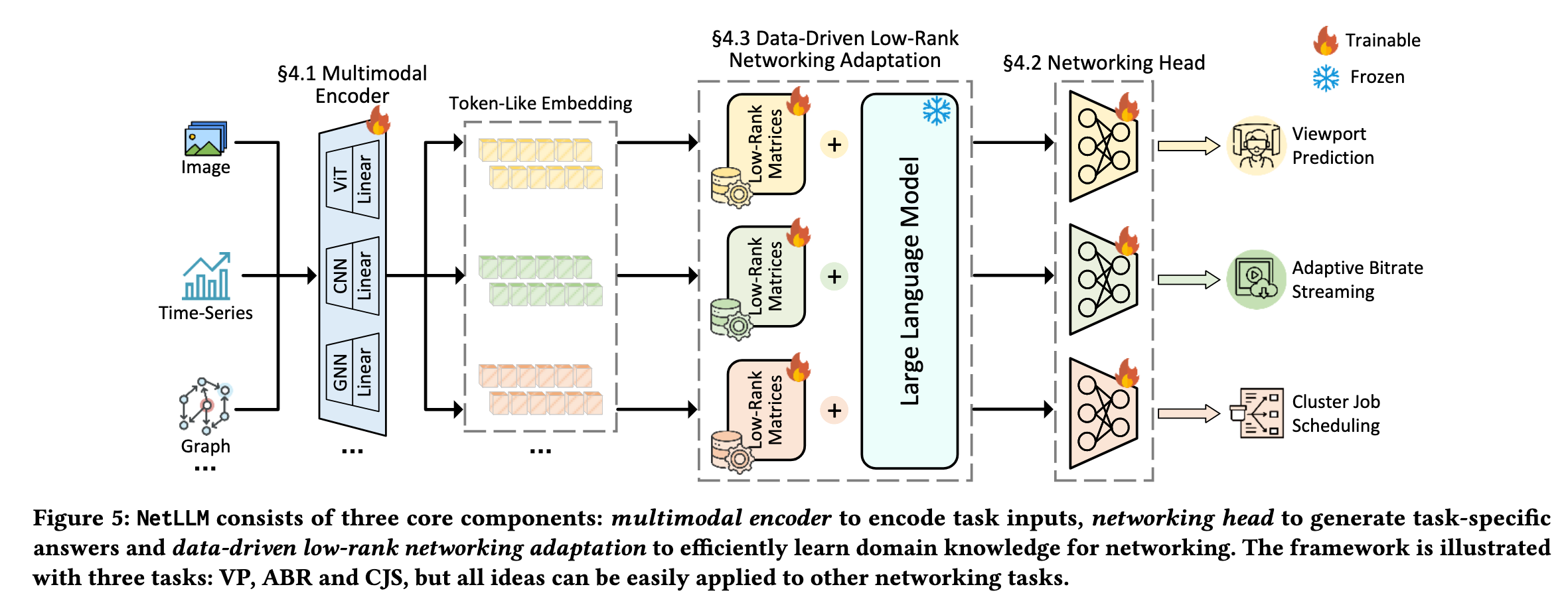
NetLLM 论文阅读笔记 (3)
第 5 章:实验评估 (Evaluation)
实验设置速览
| 配置项 | 内容 |
|---|---|
| 基础模型 | Llama2-7B(默认),另测试 OPT / Mistral / LLaVa |
| 评估任务 | VP(视口预测)/ ABR(自适应码率)/ CJS(集群作业调度) |
| 学习范式 | VP: SL;ABR/CJS: RL |
| 基线算法 | VP: TRACK / LR / Velocity;ABR: GENET / BBA / MPC;CJS: Decima / FIFO / Fair |
| 评估指标 | VP: MAE↓;ABR: QoE↑;CJS: JCT↓ |
| 硬件环境 | 8×Xeon Gold 5318Y + 2×A100 40GB |
主实验结果:相同分布环境下的性能对比(图 10)
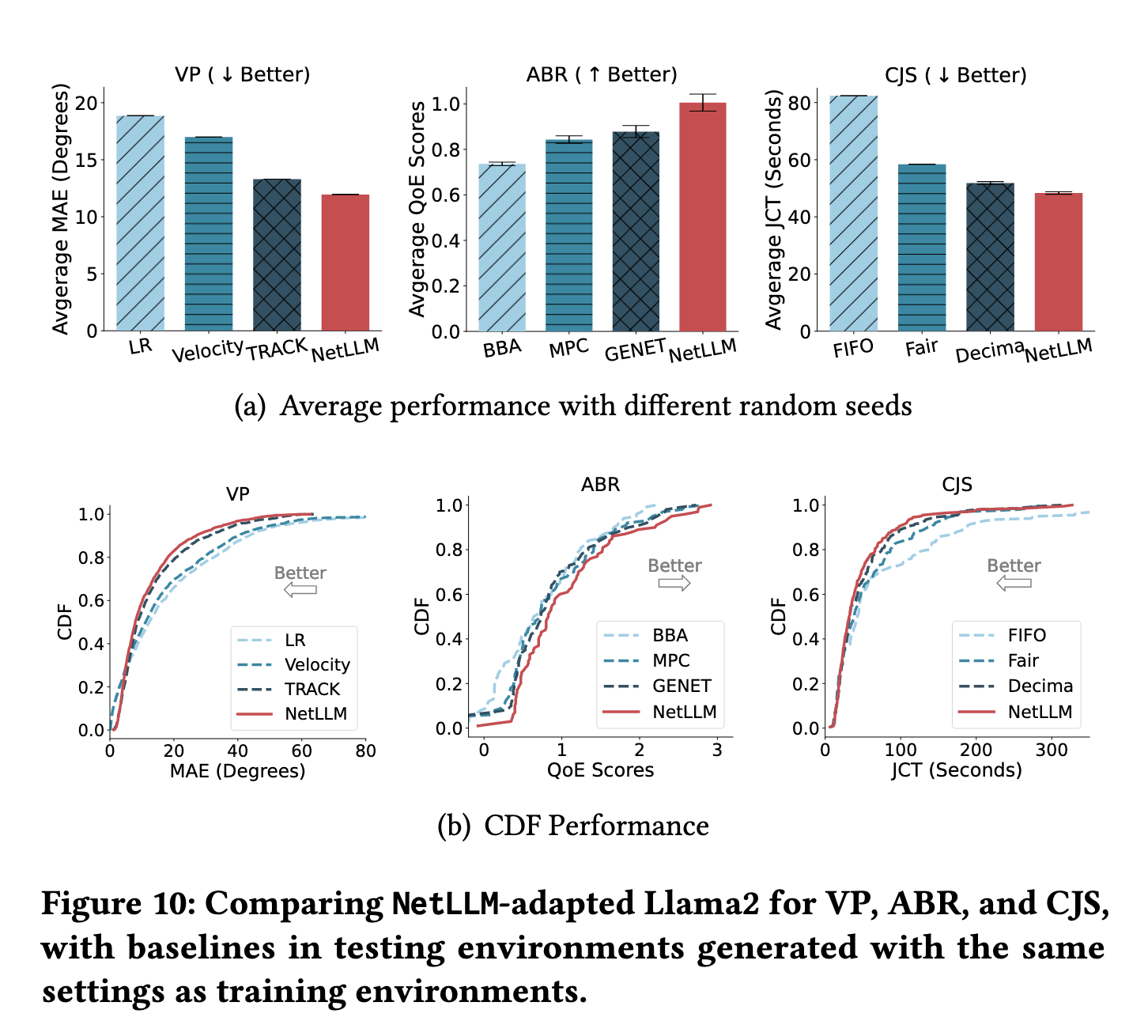
🔹 VP 任务:视口预测误差(MAE↓)
NetLLM vs TRACK: MAE 降低 10.1-36.6%- 关键结论:在多视频、多用户测试集上,NetLLM consistently 优于 SOTA
🔹 ABR 任务:用户体验质量(QoE↑)
NetLLM vs GENET: QoE 提升 14.5-36.6%- 关键结论:更好平衡码率、卡顿、波动三要素
🔹 CJS 任务:作业完成时间(JCT↓)
NetLLM vs Decima: JCT 降低 6.8-41.3%- 关键结论:更优的资源调度策略,减少长尾作业延迟
泛化能力验证:未见环境下的鲁棒性(图 11-12)
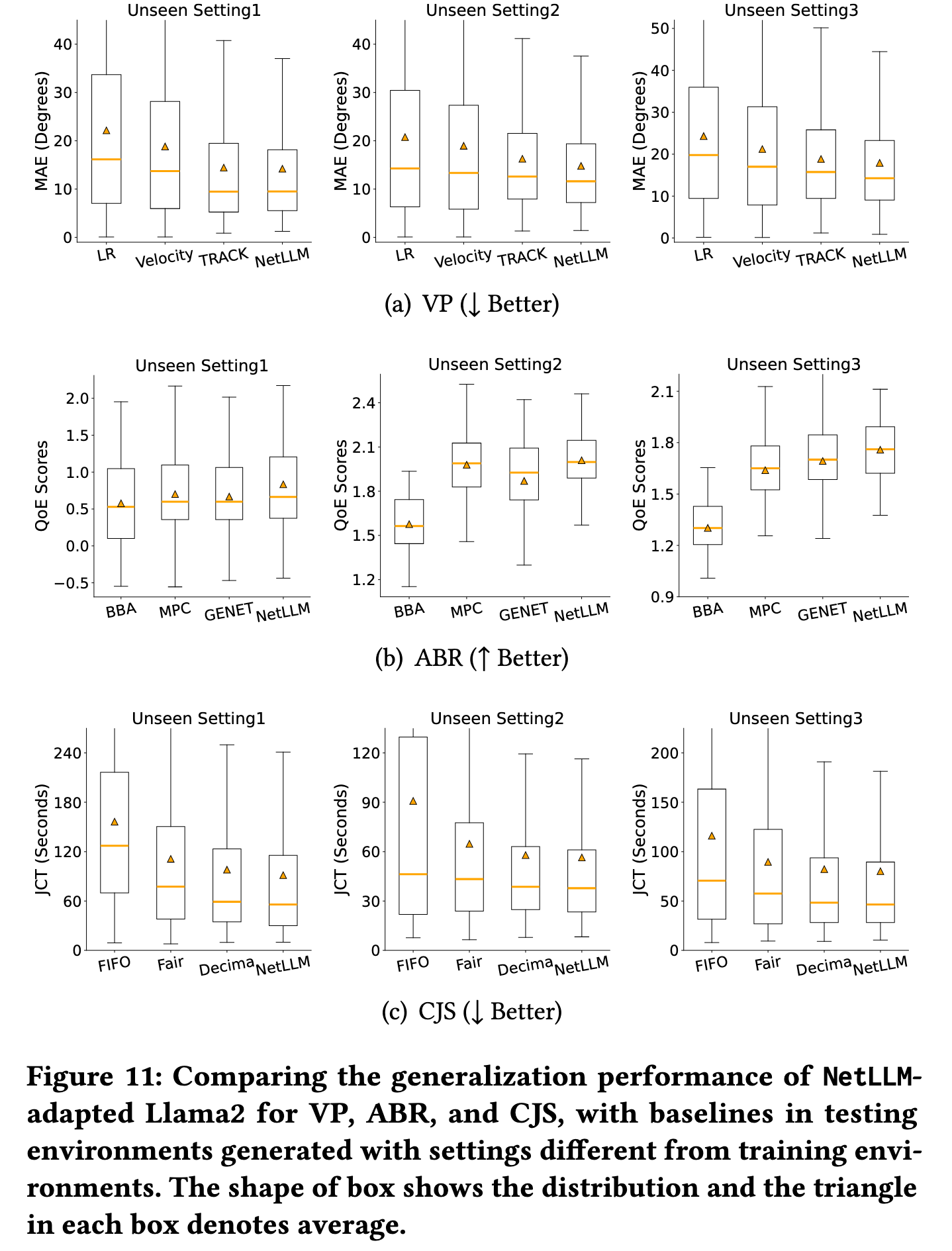
🔹 测试设置
- VP:新视频数据集(Wu2017)+ 更长预测窗口
- ABR:新带宽轨迹(动态波动更强)+ 新视频内容
- CJS:更多作业请求 + 更少计算资源
🔹 关键结果
| 任务 | NetLLM 相对基线优势 |
|---|---|
| VP | MAE 降低 1.7-9.1% |
| ABR | QoE 提升 3.9-24.8% |
| CJS | JCT 降低 2.5-6.8% |
🔹 典型案例分析(图 12:ABR 任务 QoE 分解)
- GENET 在 unseen setting 1/2 下被规则算法 MPC 超越
- 原因:无法适应新视频内容 / 动态带宽波动
- NetLLM 凭借预训练知识,在三要素间保持更好平衡
📌 Figure suggestion: Figure 11(三任务泛化箱线图)+ Figure 12(ABR QoE 分解条形图)
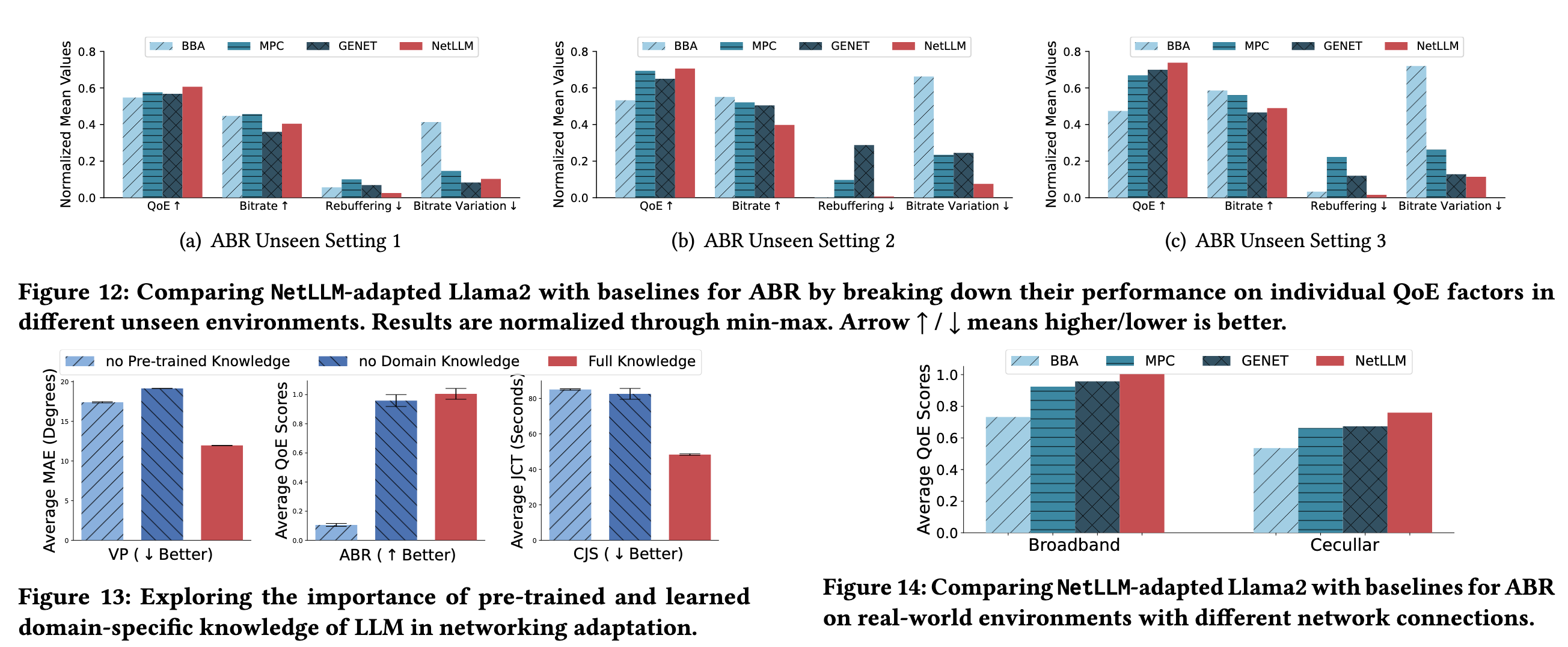
深入分析:消融实验与开销评估(图 13-16)
🔹 预训练知识 & 领域知识的重要性(图 13)
• 移除预训练权重 → 性能大幅下降(三任务均显著退化)
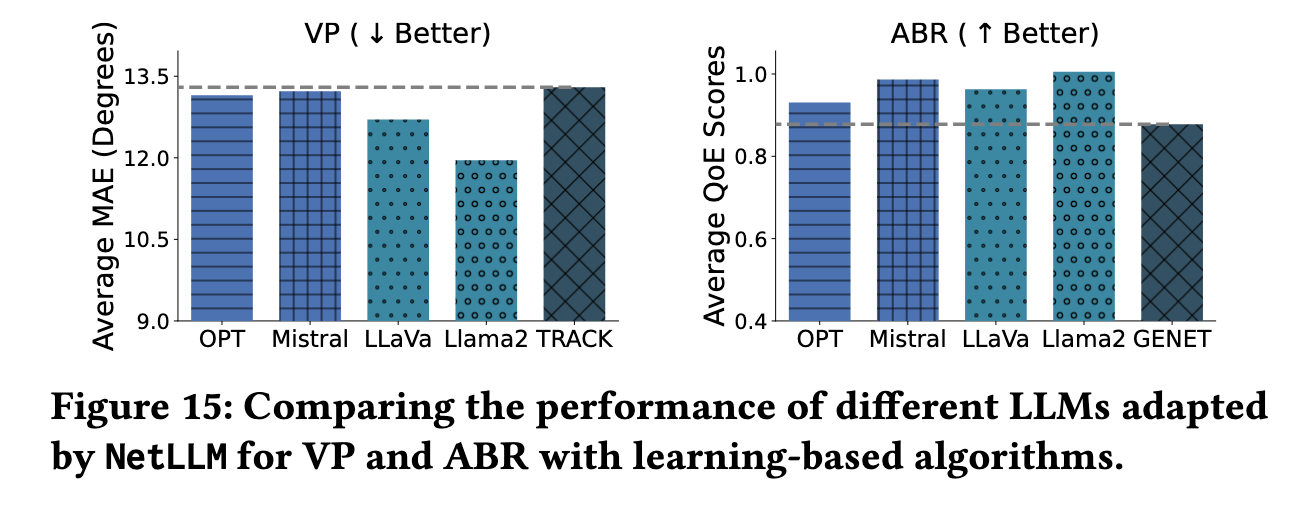
• 移除低秩适配模块 → 性能下降(验证领域知识学习必要性)🔹 不同 LLM 类型的适配效果(图 15)
- OPT / Mistral / Llama2 均显著优于基线
- 多模态 LLM(LLaVa)表现略逊于单模态 Llama2
- 结论:网络任务的多模态融合与 NLP/视觉任务不同,需专门设计
** **
🔹 不同模型规模的影响(图 16)
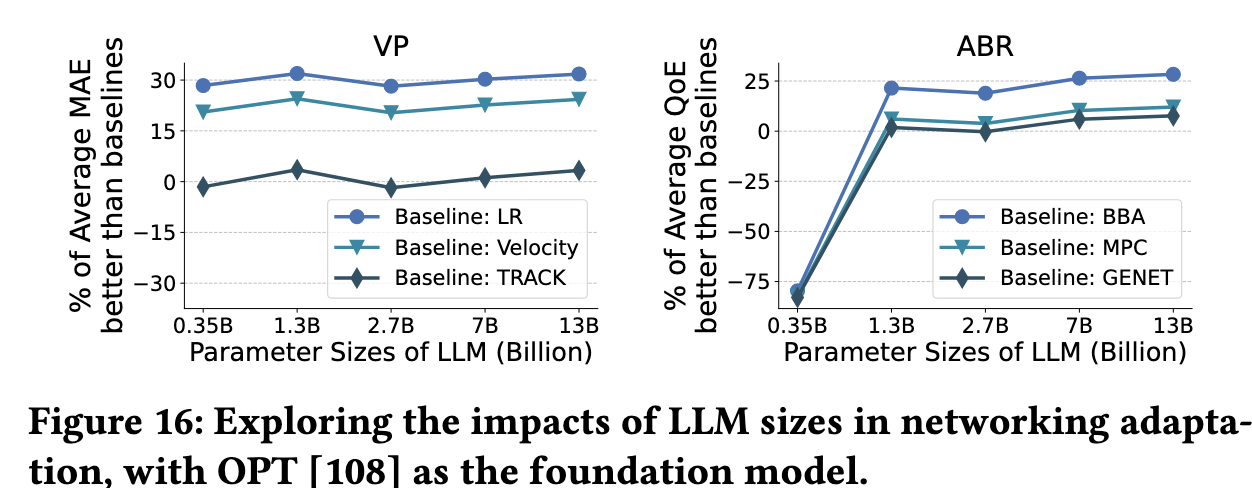
• 参数 > 1B:适配效果稳定优于基线
• 参数 < 1B(如 OPT-0.35B):性能显著下降
• 建议:实际部署选择 ≥1B 参数的 LLM🔹 计算开销评估
| 模型 | 显存占用 | 单答案生成延迟 |
|---|---|---|
| Llama2-7B | ~29GB | 0.1-0.3s |
| OPT-1.3B | ~7GB | ~0.04s |
📌 Figure suggestion: Figure 13/15/16 + 关键数字高亮(0.31%, 60.9%, 1.3B)
第 6 章:结论与展望 (Conclusion)
核心贡献(一句话总结)
NetLLM 是首个将 LLM 高效适配到网络领域的框架,通过多模态编码 + 任务头 + 低秩微调三模块设计,实现”一模型多任务”,在三个代表性任务上性能提升 10.1-41.3%,且泛化能力更强。
局限与未来方向(简要)
| 方向 | 简要说明 |
|---|---|
| 计算开销 | 大模型部署仍需资源优化(可结合剪枝/量化/蒸馏) |
| 多模态潜力 | 当前多模态 LLM 知识未必直接适用于网络任务,需进一步探索 |
| 可解释性 | 需研究 LLM 决策机制,提升可信度与可调试性 |
研究启示(可选)
- 方法论:“冻结主干 + 轻量适配”范式可迁移到其他领域适配场景
- 技术点:离线数据驱动 + 低秩微调(类 LoRA)是降低大模型适配成本的有效路径
- 应用前景:若未来出现更轻量、多模态原生支持的 LLM,NetLLM 框架可进一步降低部署门槛